- 01. Modelo Relacional
- 02. Álgebra Relacional
- 03. Cálculo Relacional de Tuplas
- 04. Expresividad
- 05. Normalización
- 06. XML
- 07. Open Data
- 09. noSQL
- 10. Data Warehousing
- 14. Schedules
- 15. Control de Concurrencia
- 16. Logging
- 17. Long Duration Transactions
- 18. In-Memory databases
- 19. Distributed Databases
- Interconexión
- Transparencia
- Disponibilidad y Confiabilidad
- Escalabilidad y Particiones
- Autonomía
- Ventajas
- Transparencia total
- Esquemas de fragmentación
- Replicación total
- Replicación parcial
- Control de concurrencia y Recovery
- Control de Concurrencia
- Transacciones
- 2PC
- Queries distribuídos
- Tipos de DDB
- Arquitecturas Paralelas vs Distribuídas
- Catálogo distribuído
- 20. Integración de Datos
- 21. Ontology-based Data Access
- 22. Gobierno y Calidad de Datos
- 23. Diseño Avanzado
- 24. Data Mining
01. Modelo Relacional
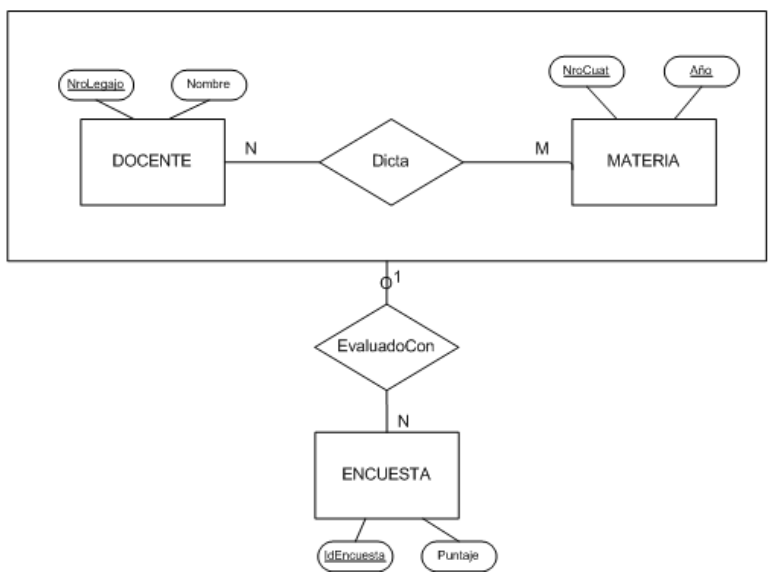
Modelo Entidad-Relacion (MER)
Herramienta que permite realizar una abstracción o modelo de alguna situación de interés presente en el mundo real. - Se representa mediante un DER (Diagrama Entidad-Relación).
Clasificación
- Cardinalidad
- Uno a uno (one-to-one)
- Uno a muchos (one-to-many)
- Muchos a muchos (many-to-many)
- Participación
- Total
- Parcial
Notación
- Database Systems - The complete book (Molina, Ullman, Widon)

- Fundamentals of Database Systems (Elmasri, Navathe)

- Cátedra (basado en Fundamentals of DB Systems)

Participación parcial
- Fundamentals of Database Systems (Elmasri, Navathe)

- Cátedra (basado en Fundamentals of DB Systems)

Roles
Cada entidad que participa en una interrelación, lo hace en un rol particular que ayuda a explicar el significado de la relación.
- Siempre deben aclararse los roles.
- En relaciones unarias, siempre debe haber al menos una participación parcial.
Atributos
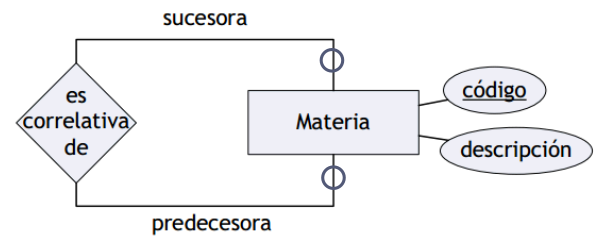
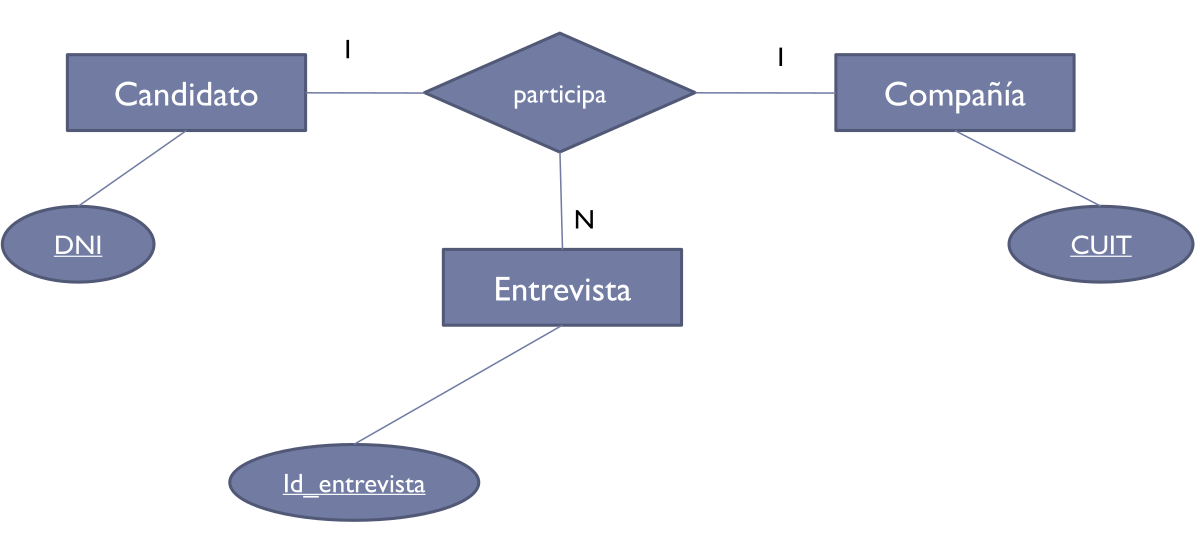
Interrelaciones ternarias
Participan tres entidades a la vez.
-
Interpretación
- "Cada candidato en una compañía puede realizar N entrevistas"
- "Cada entrevista de un candidato corresponde a una compañía"
- "Cada entrevista de una compañía corresponde a un candidato"
-
Cada entidad participa siempre en un elemento de una relación ternaria.
- Cardinalidad: se define tomando de a dos entidades.
- Participación: se define individualmente.
Jerarquías
- Se definen subentidades, que poseen atributos especiales.
- Se utiliza la relación "es un" para indicar subentidad.
Coberturas (incompleto)
TODO:
Solapamiento (incompleto)
TODO:
Agregación
Abstracción en la cual una interrlación es tratada como una entidad de alto nivel.
Atributos
- Simple: contiene un valor único
- Legajo: 1234
- Apellido: Barrios
- Nombre: Ezequiel
- DNI: 5678
- Multivaluado: contiene varios valores
- Idiomas: {Español, Inglés}
Modelo Relacional
- Representa la DB como un conjunto de relaciones.
- Intuitivamente, una tabla con filas y columnas.
- Cada tabla es una relación, y tiene su nombre.
- Cada columna es un atributo. Se asocia a un dominio (conjunto de valores que puede tomar).
- Cada fila, denominada tupla, está formada por un conjunto de valores relacionados.
Definiciones
- Dominio: D es un conjunto de valores atómicos.
- Atributo: es el nombre del rol que ejerce algún dominio D en un esquema de relación. El dominio de Aᵢ se denota dom(Aᵢ).
- Relación: esquema (intención) y extensión (estado o instancia)
- Esquema: R(A₁, A₂, ⋯, Aₙ) consiste en una relación R y un conjunto de atributos {A₁, A₂, ⋯, Aₙ}
- Aridad: cantidad de atributos que tiene.
- Extensión: dado el esquema R(A₁, A₂, ⋯, Aₙ), la extensión r(R) = {t₁, t₂, ⋯, tₘ}, conjunto de tuplas
- ∀
- Definición alternativa, t = {v₁, v₂, ⋯, vₙ} si consideramos el orden dentro de la tupla.
- ∀
- La extensión es subconjunto del producto cartesiano de una lista de dominios.
- r(R) ⊆ (dom(A_1) × dom(A_2) × ⋯ × dom(Aₙ))
Interpretación
- CWA: closed world assumption
- The closed-world assumption (CWA), in a formal system of logic used for knowledge representation, is the presumption that a statement that is true is also known to be true. Therefore, conversely, what is not currently known to be true, is false.
- The opposite of the closed-world assumption is the open-world assumption (OWA), stating that lack of knowledge does not imply falsity.
Claves
Conjunto minimal de atributos que definen unívocamente a las tuplas.
- Sea K: clave, E: relación, eᵢ eⱼ: tuplas
- ∀(eᵢ, ejⱼ ∈ E): eᵢ.K = eⱼ.K ⟹ eᵢ = eⱼ
- Varias claves candidatas (CK = Candidate Keys)
- Una clave primaria (PK = Primary Key)
- Referencias a claves de otras relaciones claves externas/foráneas (FK = Foreign Keys)
Superclaves (incompleto)
TODO:
Restricciones / Constraints
Una Integrity Constraint es básicamente una expresión booleana que tiene que evaluar a true.
- Una relational database schema S es un conjunto de relaciones {R₁, R₂, ⋯, Rₘ} y un conjunto de integrity constraints IC.
-
Un relational database state DB of S es un conjunto de estados {r₁, r₂, ⋯, rₘ} tal que rᵢ es una instancia de Rᵢ y que la relación rᵢ satisface los integrity constraints especificados en IC.
-
Las restricciones son inherentes al modelo.
- Se expresan en la definición del esquema:
- Claves
- Non-NULL
- Dominios
- Integridad referencial
- Integraidad de las relaciones
Transformación de MER a MR (incompleto)
TODO:
Consideraciones de diseño (incompleto)
TODO:
02. Álgebra Relacional
Conjunto de elementos junto con sus propiedades operacionales determinadas y las propiedades matemáticas que dichas operaciones poseen.
- Lenguaje formal utilizado en el modelo relacional.
- Permite especificar consultas sobre instancias de relaciones.
- También implementar y optimizar.
-
El resultado es una nueva relación.
-
Técnica: procedural/axiomática (importa el orden de evaluación)
-
Operadores: toman relaciones y devuelven relaciones
- Unarios
- Binarios
Select
Selecciona un subconjunto de tuplas de una relación a través de una condición lógica.
- Notación: σ<condicion>(R).
- Genera una partición horizontal de la relación.
EMPLEADO
| dni | nombre | sexo | salario |
|---|---|---|---|
| 1 | Diego | M | 20000 |
| 2 | Laura | F | 25000 |
| 3 | Marina | F | 10000 |
-
σ<sexo=F>(EMPLEADO)
dni nombre sexo salario 2 Laura F 25000 3 Marina F 10000 -
σ
dni nombre sexo salario 2 Laura F 25000
Propiedades:
- Operador Unario
- Grado(σ(R)) = Grado(R) (misma aridad que la relación)
- #tuplas: |σ(R)| ≤ |R|
- Conmutatividad: σ₁(σ₂(R)) = σ₂(σ₁(R))
- Cascada: σ₁(σ₂(⋯(σₙ(R))⋯)) = σ<1 and 2 and ⋯ and n>(R)
- SQL: se especifica en la cláusula WHERE, se corresponden:
- σ
- SELECT * FROM EMPLEADO WHERE sexo=F AND salario>15000;
- σ
Project
Selecciona un subconjunto de columnas de una relación
- Notación: π<lista de atributos>(R)
- Genera una partición vertical de la relación.
EMPLEADO
| dni | nombre | sexo | salario |
|---|---|---|---|
| 1 | Diego | M | 20000 |
| 2 | Laura | F | 25000 |
| 3 | Marina | F | 10000 |
-
π<dni,salario>(EMPLEADO)
dni salario 1 20000 2 25000 3 10000
Propiedades
- Operador Unario
- Grado(π<lista de atributos>(R)) = |
| - #tuplas: |π<lista de atributos>(R)| ≤ |R|
- Remueve las tuplas duplicadas
- Conservación de # tuplas: si
es superclave de R, entonces |π<lista de atributos>(R)| = |R|
- No es conmutativa.
- π<lista₁>(π<lista₁>(R)) = π<lista1>(R) ⟹ lista₁ ⊆ lista₂
- SQL: se especifica en la cláusula SELECT DISTINCT, se corresponden:
- π<sexo,salario>(EMPLEADO)
- SELECT DISTINCT Sexo,Salario FROM EMPLEADO;
Rename
Asigna nombre a atributos/relación resultado.
- Notación: ρ<NOMBRE_RESULTADO>(R) o ρ(A₁→B₁, ⋯, Aₙ→Bₙ, R)
Ejemplo 1: Relaciones
EMPLEADO
| dni | nombre | sexo | salario |
|---|---|---|---|
| 1 | Diego | M | 20000 |
| 2 | Laura | F | 25000 |
| 3 | Marina | F | 10000 |
Son equivalentes:
- π<nombre,sexo>(σ<salario≥15000>(empleado))
y
-
ρ<SALARIO_MAYOR>(σ<salario≥15000>(EMPLEADO))
SALARIO_MAYOR
dni nombre sexo salario 1 Diego M 20000 2 Laura F 25000 -
ρ<RESULT>(π<nombre,sexo>(SALARIO_MAYOR))
RESULT
nombre sexo Diego M Laura F
Ejemplo 2: Atributos
EMPLEADO
| dni | nombre | sexo | salario |
|---|---|---|---|
| 1 | Diego | M | 20000 |
| 2 | Laura | F | 25000 |
| 3 | Marina | F | 10000 |
- SQL: se especifica en la cláusula AS, se corresponden:
-
ρ<EMP(dni→id, salario→ingreso)>(π<dni,salario>(EMPLEADO))
id ingreso 1 20000 2 25000 3 10000 + SELECT EMP.dni AS id, EMP.salario as Ingreso FROM EMPLEADO AS EMP
-
Union, Intersection, Minus
Equivalente a operaciones matemáticas sobre conjuntos
- Notación: R∪S, R∩S, R−S
- Sin duplicados. La relación resultante no contiene duplicados.
- Unión compatible: R(A₁, ⋯, Aₙ) y S(B₁, ⋯, Bₙ) son unión compatibles (o compatibles por tipos) si:
- Ambas tienen grado n
- (∀i, 1≤i≤n) tipo(Aᵢ) = tipo(Bᵢ)
ALUMNOS_BD
| id | nombre |
|---|---|
| 1 | Diego |
| 2 | Laura |
| 3 | Marina |
ALUMNOS_TLENG
| id | nombre |
|---|---|
| 2 | Laura |
| 4 | Alejandro |
-
Union: R∪S, incluye todas las tuplas que están en R, en S, o en ambas a la vez, eliminando duplicados.
-
ρ<UNION>(ALUMNOS_BD ∪ ALUMNOS_TLENG)
UNION
id nombre 1 Diego 2 Laura 3 Marina 4 Alejandro
-
-
Intersection: R∩S, incluye todas las tuplas que están a la vez en R y S.
-
ρ<INTERSECCION>(ALUMNOS_BD ∩ ALUMNOS_TLENG)
INTERSECCION
id nombre 2 Laura
-
-
Set difference (o minus): R−S, incluye todas las tuplas que están en R, pero no están en S.
-
ρ<DIFERENCIA>(ALUMNOS_BD ∩ ALUMNOS_TLENG)
DIFERENCIA
id nombre 1 Diego 3 Marina
-
-
Por convención la relación resultante conserva los nombres de atributo de la primer relación.
-
Conmutatividad
- R∪S = S∪R
- R∩S = S∩R
- R−S ≠ S−R (en el caso general)
- Asociatividad
- R∪(S∪T) = (R∪S)∪T
- R∩(S∩T) = (R∩S)∩T
-
Equivalencia: R∪S = ((R∪S)−(R−S)) − (S−R)
-
SQL:
- UNION, INTERSECT, EXCEPT funcionan como en AR.
- UNION ALL, INTERSECT ALL, EXCEPT ALL no eliminan duplicados.
Cartesian Product
Produce una nueva relación que combina cada tupla de una relación con las de la otra relación.
- Notación: R×S
PERSONA
| nombre | nacionalidad |
|---|---|
| Diego | AR |
| Laura | BR |
| Marina | AR |
NACIONALIDADES
| idn | detalle |
|---|---|
| AR | Argentina |
| BR | Brasilera |
| CH | Chilena |
- ρ
(PERSONA×NACIONALIDADES)
RESULT
| nombre | nacionalidad | idn | detalle |
|---|---|---|---|
| Diego | AR | AR | Argentina |
| Diego | AR | BR | Brasilera |
| Diego | AR | CH | Chilena |
| Laura | BR | AR | Argentina |
| Laura | BR | BR | Brasilera |
| Laura | BR | CH | Chilena |
| Marina | AR | AR | Argentina |
| Marina | AR | BR | Brasilera |
| Marina | AR | CH | Chilena |
- No hace falta que las relaciones sean UNION COMPATIBLE.
- Grado: T=R×S ⟹ grado(T) = grado(R) + grado(S)
- SQL: CROSS JOIN
Join
Permite combinar pares de tuplas relacionadas
- Notación: R⋈<condicion>S
PERSONA
| nombre | nacionalidad |
|---|---|
| Diego | AR |
| Laura | BR |
| Marina | AR |
NACIONALIDADES
| idn | detalle |
|---|---|
| AR | Argentina |
| BR | Brasilera |
| CH | Chilena |
- ρ
(PERSONA⋈
RESULT
| nombre | nacionalidad | idn | detalle |
|---|---|---|---|
| Diego | AR | AR | Argentina |
| Laura | BR | BR | Brasilera |
| Marina | AR | AR | Argentina |
-
Solo aparecen las combinaciones de tuplas que satisfacen la condición
= AND and ... and = AᵢθBⱼ con Aᵢ atributo de R y Bⱼ atributo de S - dom(Aᵢ) = dom(Bⱼ)
- θ ∈ {=, <, ≤, >, ≥, ≠}
- Si los atributos son NULL o la condición es falsa no aparecen en el resultado.
-
EQUIJOIN: JOIN en donde se utiliza la operación =
-
Duplicación de campos (ej nacionalidad e idn)
RESULT_EQUIJOIN
nombre nacionalidad idn detalle Diego AR AR Argentina Laura BR BR Brasilera Marina AR AR Argentina
-
-
NATURAL JOIN: Deja solo uno de los campos duplicados
- Notación: R⋈S (también R*S)
-
Los campos del join deben tener el mismo nombre, o hacer un rename previo.
RESULT_NATURALJOIN
nombre nacionalidad detalle Diego AR Argentina Laura BR Brasilera Marina AR Argentina
-
Tamaño resultado JOIN(S,R): puede ir de 0 a S*R registros.
- Selectividad de JOIN(S,R): es una tasa, y corresponde a |JOIN(S,R)|/(|S|*|R|)
- SQL: SELECT persona.nombre, persona.nacionalidad, nacionalidades.detalle from persona, nacionalidades where persona.nacionalidad=nacionalidades.idn;
PERSONA
| nombre | nacionalidad |
|---|---|
| Diego | BR |
| Laura | NULL |
| Marina | AR |
| Santiago | UY |
NACIONALIDADES
| idn | detalle |
|---|---|
| AR | Argentina |
| BR | Brasilera |
| CH | Chilena |
| US | Estadounidense |
-
Inner Join: las tuplas que no cumplen la condición son eliminadas (ej, si el atributo es null)
RESULT_INNERJOIN
nombre nacionalidad idn detalle Diego BR BR Brasilera Marina AR AR Argentina -
Outer Join: se incorpora las tuplas de R, S o ambas que no cumplen la condición de JOIN.
RESULT_OUTERJOIN
nombre nacionalidad idn detalle Diego BR BR Brasilera Laura NULL NULL NULL Marina AR AR Argentina Santiago UY NULL NULL NULL NULL US Estadounidense -
Left Outer Join: conserva todas las tuplas de R. Si no se encuentra ninguna de S que cumpla con la condición de join, los atributos de S en el resultado se completan con NULL.
RESULT_LEFTOUTERJOIN
nombre nacionalidad idn detalle Diego BR BR Brasilera Laura NULL NULL NULL Marina AR AR Argentina Santiago UY NULL NULL -
Right Outer Join: conserva todas las tuplas de S. Si no se encuentra ninguna de R que cumpla con la condición de join, los atributos de R en el resultado se completan con NULL.
RESULT_RIGHTOUTERJOIN
nombre nacionalidad idn detalle Diego BR BR Brasilera Marina AR AR Argentina NULL NULL US Estadounidense -
Full Outer Join: conserva todas las tuplas de R y S. Si no se encuentra ninguna de R o S que cumpla con la condición de JOIN, entonces sus atributos se completan con NULL.
RESULT_FULLOUTERJOIN
nombre nacionalidad idn detalle Diego BR BR Brasilera Laura NULL NULL NULL Marina AR AR Argentina Santiago UY NULL NULL NULL NULL US Estadounidense
TODO: ¿esto es lo mismo que outer join?
Division
Retorna los valores de R que están emparejados con todos los valores de S.
- Notación: R÷S.
- Requiere que atributos(S) ⊂ atributos(R).
- Resultado contiene atributos(S) − atributos(R).
ALUMNOS
| nombre | materia |
|---|---|
| diego | bd |
| diego | plp |
| laura | bd |
| laura | plp |
| laura | tleng |
| marina | bd |
| marina | tleng |
| santiago | bd |
| santiago | plp |
| santiago | tleng |
MATERIAS_1
| materia |
|---|
| bd |
MATERIAS_2
| materia |
|---|
| bd |
| tleng |
MATERIAS_3
| materia |
|---|
| bd |
| plp |
| tleng |
ALUMNOS÷MATERIAS_1
| nombre |
|---|
| diego |
| laura |
| marina |
| santiago |
ALUMNOS÷MATERIAS_2
| nombre |
|---|
| laura |
| marina |
| santiago |
ALUMNOS÷MATERIAS_3
| nombre |
|---|
| laura |
| santiago |
- Operación compuesta: se puede expresar como secuencia de operaciones (π, ×, −). Ejemplo, son equivalentes:
- ALUMNOS÷MATERIAS_3
- ρ<TEMP1>(π<nombre>(ALUMNOS))
- ρ<TEMP2>(π<nombre>((TEMP1×MATERIAS_3)−ALUMNOS))
- ρ<RESULT>(TEMP1−TEMP2)
TEMP_1
| nombre |
|---|
| diego |
| laura |
| marina |
| santiago |
TEMP_2
| nombre |
|---|
| diego |
| marina |
TEMP_3
| nombre |
|---|
| laura |
| santiago |
Bibliografía
- Capítulo 6 (hasta 6.5 inclusive), Elmasri/Navathe - Fundamentals of Database Systems, 6th Ed., Pearson, 2011
03. Cálculo Relacional de Tuplas
Lenguaje de consultas al igual que Álgebra Relacional
- Declarativo (no tiene un orden de evaluación, no es procedural)
- Tiene fundamento en lógica matemática
-
SQL tiene fundamentos en CRT
-
Notación:
{t | COND(t)}tes una variable de tipo tupla.tes la única variable libre de la expresión.
COND(t)es una expresión booleana condicional que afecta at.COND(t)es una fórmula bien formada- Formada por alguno de los siguientes predicados atómicos:
r ∈ Rr.A op s.Br.A op coc op R.a- ...en donde
Res una relación,rysson tuplas,AyBson atributos,ces un valor constante yopes un operador de conjunto{=, <, ≤, >, ≥, ≠}.
- Cada predicado atómico tiene un valor de verdad:
- Si
rtoma el valor de una tupla que pertenece a la relaciónR, el predicado es verdadero. - Si el valor que toman los atributos de
ryssatisfacen la condición, el predicado es verdadero. - Si el valor que toma el atributo de
rsatisface la condición, el resultado es verdadero.
- Si
- Se define recursivamente de la siguiente manera:
- Todo predicado atómico es una fórmula.
(F₁ ∧ F₂),(F₁ ∨ F₂),(¬F₁)son fórmulas, dondeF₁yF₂son fórmulas.(∃r)(F). Es una fórmula siFes una fórmula en donde la variable de tipo tuplaraparece al menos una vez de manera libre. Es verdadera cuando existe un valor derque satisfagaF.(∀r)(F). Es una fórmula siFes una fórmula en donde la variable de tipo tuplaraparece al menos una vez de manera libre. Es verdadera cuando todos los valores dersatisfacenF.
- Formada por alguno de los siguientes predicados atómicos:
- El resultado es el conjunto de todas las tuplas
tque satisfacenCOND(t).
Ejemplos
EMPLEADO
| dni | nombre | salario | depto | supervisor |
|---|---|---|---|---|
| 20222333 | Diego | 20000 | IN | 33456234 |
| 33456234 | Laura | 25000 | IN | |
| 45432345 | Marina | 10000 | IN | 33456234 |
| 12323212 | Beatriz | 12000 | RH | 12323212 |
| 34323232 | Pedro | 17000 | RH | |
| 11232123 | María | 55000 | GG |
DEPARTAMENTO
| idd | detalle |
|---|---|
| IN | Investigación |
| RH | RRHH |
| GG | Gerencia General |
- Listar nombre y salario de aquellos empleado que trabajan en el Departamento cuyo detalle es RRHH.
{t | (∃e)(∃d)(e∈EMPLEADO ∧ d∈DEPARTAMENTO ∧ d.detalle='RRHH' ∧ e.depto=d.idd ∧ t.nombre=e.nombre ∧ t.salario=e.salario)}.
- Listar nombre, salario y nombre de departamento de aquellos empleados que ganan más de 15000.
{t | (∃e)(e∈EMPLEADO ∧ d∈departamento ∧ e.salario>15000 ∧ e.depto=d.idd ∧ t.nombre=e.nombre ∧ t.salario=e.salario ∧ t.departamento=d.detalle)}
-
- Listar el nombre de cada empleado junto al de su supervisor.
{t | (∃e)(∃s)(e∈EMPLEADO ∧ s∈EMPLEADO ∧ e.supervisor=s.dni ∧ t.nombre=e.nombre ∧ t.supervisor=s.nombre}
- Listar el nombre de cada empleado del Departamento de investigación junto al de su supervisor.
{t | (∃e)(∃s)(e∈EMPLEADO ∧ s∈EMPLEADO ∧ e.depto='IN' ∧ e.supervisor=s.dni ∧ t.nombre=e.nombre ∧ t.supervisor=s.nombre}
- Listar el nombre de cada empleado junto al de su supervisor.
- Listar el nombre de los empleados que trabajan en RRHH o que su supervisor gana más de 15000
text {t | (∃e)(e∈EMPLEADO ∧ ( (e.dpto='RH') ∨ (∃s)(s∈EMPLEADO ∧ e.supervisor=s.dni ∧ s.salario>15000) ) ∧ t.nombre=e.nombre)} - Listar los empleados que no tienen supervisor asignado
{t | (∃e)(e∈EMPLEADO ∧ (∀s)(s∈EMPLEADO ⟹ e.supervisor≠s.dni) ∧ t.nombre=e.nombre)}
04. Expresividad
Es la amplitud de ideas que pueden ser representadas por un lenguaje.
- más expresividad ⟹ más variedad y cantidad de ideas
- equivale a la cantidad de consultas que pueden hacerse
Comparación CRT vs LPO
CRT es una especialización de LPO.
- Cada relación es la interpretación de un predicado.
- CRT tiene semántica restringida, el modelo es fijo.
CRT - Expresiones seguras
- Dominio de expresión CRT:
dom(E)es el conjunto de valores:- Constantes en
E - pertenecientes a cualquier atributo de cualquier tupla de las relaciones mencionadas en E
- Ejemplo:
dom({t | (t∈EMPLEADO)})es el conjunto de todos los valores que toman los atributos de todas las tuplas de la relaciónEMPLEADO.
- Constantes en
- Expresión segura: produce cantidad finitas de resultados.
- Ejemplo de expresión insegura:
{t | ¬(EMPLEADO)}produce todo el universo posible de empleados que no forman parte de la relación EMPLEADO. - Una expresión es segura si todos los valores en el resultado son parte del dominio de la expresión.
- Ejemplo de expresión insegura:
- CRT restringido a expresiones seguras es equivalente en poder de expresividad al AR básica.
Comparación CRT vs AR
Bajo ciertas condiciones, CRT tiene el mismo poder expresivo que Álgebra Relacional.
CRD - Cálculo Relacional de Dominio
- CRT utiliza tuplas a modo de variables
- CRD utiliza atributos a modo de variables
- CRD tiene el mismo poder de expresividad que CRT
Propiedades NO expresables
- Existen ciertas propiedades que no pueden ser expresadas en LPO.
- Ver: Teorema Ehrenfeucht-Fraisse.
TODO: Hace falta estudiar el teorema este? Suena al pedo.
SQL
- La semántica de SQL está basada en AR, por lo que ese es su poder expresivo.
- Hay implementaciones que proveen predicados "extra-lógicos" que permiten mayor expresividad:
- Recursión
- Funciones de agregación y agrupamiento
- Operaciones sobre atributos (ej. aritméticas)
- Store procedures
- Etc...
Bibliografía
- Ehrenfeucht-Fraïssé games, Math Explorers Club, Cornell Department of Mathematics. http://www.math.cornell.edu/~mec/Summer2009/Raluca
- Libkin. Elements of Finite Model Theory. Springer. 2012.
- Expressive Power of SQL. Leonid Libkin: https://homepages.inf.ed.ac.uk/libkin/papers/icdt01.pdf
05. Normalización
Marco general
- Salida del diseño -> conjunto de relaciones
- Calidad del diseño -> ¿una forma de agrupar atributos es mejor que otra?
- Niveles
- Lógico (o conceptual)
- Implementación (o de almacenamiento físico)
- Objetivos
- Preservar la información
- Minimizar la redundancia
Pautas de diseño (SANE)
- Semántica: Estar seguro de que la semántica de atributos en el esquema es clara
- Almacenamiento: Reducir la información redundante en las tuplas
- Reducir la cantidad de valores NULL en las tuplas
-
Deshabilitar la posibilidad de generar tuplas espúreas
-
Estas pautas no son siempre independientes entre sí.
Pauta 1: Semántica
Objetivo: cuanto más fácil es explicar la semántica en los esquemas, mejor es el diseño
- Mal diseño:
EMPLEADO_PROYECTO: {E_NOMBRE, E_DNI, E_NACIMIENTO, DIRECCION, P_NOMBRE, P_NUMERO} - Buen diseño:
EMPLEADO{E_NOMBRE, E_DNI, E_NACIMIENTO, DIRECCION}, PROYECTO{P_NOMBRE, P_NUMERO}, TRABAJA_EN{E_DNI, P_NUMERO}
Pautas
- Diseñar esquemas para que sea fácil explicar su significado.
- No combinar atributos de distintos tipos de entidades y relaciones en una misma relación.
Pauta 2: Almacenamiento
Objetivo: minimizar el espacio de almacenamiento a través del diseño.
-
Mal diseño:
EMPLEADO_DEPARTAMENTO{E_NOMBRE, E_DNI, NRO_DPTO, D_NOMBRE}- EMPLEADO_DEPARTAMENTO
E_NOMBRE E_DNI NRO_DPTO D_NOMBRE Diego 11111 5 Publicidad y Promoción Laura 22222 5 Publicidad y Promoción Marina 33333 2 Reclutamiento y Selección Santiago 44444 5 Publicidad y Promoción ........ ..... ........ ........................ -
Bueno diseño:
EMPLEADO{E_NOMBRE, E_DNI, NRO_DPTO}, DEPARTAMENTO{NRO_DPTO, D_NOMBRE}- EMPLEADO
E_NOMBRE E_DNI NRO_DPTO Diego 11111 5 Laura 22222 5 Marina 33333 2 Santiago 44444 5 ........ ..... ........ - DEPARTAMENTO
NRO_DPTO D_NOMBRE 5 Publicidad y Promoción 2 Reclutamiento y Selección -
Un mal diseño puede generar anomalías de actualización (inserción, eliminación, actualización).
Anomalías de inserción
-
Insertar un empleado que aún no posee departamento requiere introducir valores
NULLE_NOMBRE E_DNI NRO_DPTO D_NOMBRE (Problema) Santiago 44444 5 Publicidad y Promoción Tamara 55555 NULL NULL <- Campos NULL ........ ..... ........ ........................ -
Insertar un nuevo empleado requiere que los datos sean consistentes con el resto de los registros.
E_NOMBRE E_DNI NRO_DPTO D_NOMBRE (Problema) Santiago 44444 5 Publicidad y Promoción Tamara 55555 5 Publicaciones y Prop. <- Inconsistente ........ ..... ........ ........................ -
No es posible insertar un nuevo departamento que aún no posee empleados
- NULL en el campo de empleado violaría la integridad de la clave (E_DNI)
- Esa tupla dejaría de tener sentido si se asigna un empleado a ese departamento
Anomalías de eliminación
-
Eliminar el único empleado de un departamento hace que se pierda toda la información relacionada al mismo.
E_NOMBRE E_DNI NRO_DPTO D_NOMBRE (problema) Diego 11111 5 Publicidad y Promoción Laura 22222 5 Publicidad y Promoción Marina 33333 2 Reclutamiento y Selección <- Pérdida de información Santiago 44444 5 Publicidad y Promoción ........ ..... ........ ........................
Anomalías de modificación
-
Modificar el valor de un atributo de un departamento requiere modificar TODAS las tuplas de ese departamento. Sino se generan inconsistencias.
E_NOMBRE E_DNI NRO_DPTO D_NOMBRE (problema) Diego 11111 5 Publicidad, Promoción y Comunicación <- Modificado (inconsistente) Laura 22222 5 Publicidad y Promoción <- Original (inconsistente) Marina 33333 2 Reclutamiento y Selección Santiago 44444 5 Publicidad y Promoción <- Original (inconsistente) ........ ..... ........ ........................
Performance
- Esta pauta puede ser violada en favor de la performance.
- Por ejemplo, al guardar una factura, esto afecta el saldo del cliente. Este saldo se puede reconstruir recorriendo todas las facturas y pagos realizados, pero es "costoso" ya que es un dato frecuentemente consultado.
- La solución sería guardar el saldo, y recalcular el saldo en cada pago.
- Se debe utilizar algún mecanismo que permita automatizar esto último (triggers/store procedures, etc)
Pauta 3: NULLs
Atributos no relacionados agrupados en una misma tabla pueden generar múltiples NULL en una misma tupla.
EMPLEADO_DEPARTAMENTO
| E_NOMBRE | E_DNI | NRO_DPTO | D_NOMBRE |
|---|---|---|---|
| Santiago | 44444 | 5 | Publicidad y Promoción |
| Tamar | 55555 | NULL | NULL |
- Desperdicio de espacio de almacenamiento
- Problemas al hacer JOIN (
INNER JOINproduce distinto resultado queOUTER JOIN). - ¿Cómo se interpretan las funciones de agregación? (count, sum, etc)
- Diversas interpretaciones de NULL
- El resultado no aplica a la tupla.
- Ejemplo: registro de conducir en un menor.
- El valor existe, pero está ausente.
- Ejemplo: fecha de nacimiento.
- El valor es desconocido (no sabemos si existe o no)
- Ejemplo: teléfono.
- El resultado no aplica a la tupla.
Pautas
- Evitar asignar atributos a una relación si estos pueden ser NULL frecuentemente
- Si los NULL son inevitables, asegurar que sean situaciones excepcionales.
Pauta 4: Tuplas Espúreas
Las tuplas espúreas representan información no válida.
-
Esquema original EMPLEADO_PROYECTO
E_NOMBRE E_DNI NRO_PROY P_UBICACION Diego 11111 5 Argentina Laura 22222 5 Argentina Marina 33333 2 Uruguay Santiago 44444 5 Argentina -
Descomposición EMPLEADO
E_DNI NRO_PROY P_UBICACION 11111 5 Argentina 22222 5 Argentina 33333 2 Uruguay 44444 5 Argentina UBICACION_EMPLEADO
E_NOMBRE P_UBICACION Diego Argentina Laura Argentina Marina Uruguay Santiago Argentina -
Esta descomposición no permite recuperar la información original.
-
Al aplicar
NATURAL JOINse producen tuplas espúreas.E_DNI NRO_PROY P_UBICACION E_NOMBRE 11111 5 Argentina Diego 22222 5 Argentina Diego 33333 2 Uruguay Marina 44444 5 Argentina Diego -
Problema:
P_UBICACIONrelaciona ambos esquemas pero no es clave primaria ni foránea de ninguno de ellos.
Pautas
- Diseñar esquemas que puedan ser relacionads por atributos que se encuentren relacionados por condiciones de igualdad entre ellos (clave primaria/foránea).
- Evitar relaciones que contengan atributos de matching que no sean combinación de claves primaria/foránea, ya que los JOINS pueden introducir tuplas espúreas.
Dependencias funcionales
Herramienta formal para el análisis de esquemas. Permite detectar y describir problemas descriptos previamente.
- Informalmente: restricción entre dos conjuntos de atributos
XeYde una BBDD. Los valores que toman los atributos deYdependen de los valores que tomenX.
Ejemplo:
- DF1: {E_DNI, P_NUMERO} ⟹ HORAS
E_DNI, P_NUMERO, HORAS, E_NOMBRE, P_NOMBRE, P_UBICACION
----- --------
v v ^
| | |
v-------v-------^
- DF2: E_DNI ⟹ E_NOMBRE
E_DNI, P_NUMERO, HORAS, E_NOMBRE, P_NOMBRE, P_UBICACION
----- --------
v v ^
| | |
v-------v----------------^
- DF3: P_NUMERO ⟹ {P_NOMBRE, P_UBICACION}
E_DNI, P_NUMERO, HORAS, E_NOMBRE, P_NOMBRE, P_UBICACION
----- --------
v ^ ^
| | |
v---------------------------------------
-
Formalmente:
- Esquema relacional de la BD posee atributos A₁, A₂, ⋯, Aₙ
- La BD se puede pensar como un esquema universal R = {A₁, A₂, ⋯, Aₙ}
- Sean X,Y ⊆ R, la DF indicada como X⟹Y especifica una restricción sobre las posibles tuplas que pueden conformar una instancia r de R. Para cualquier par t₁,t₂ ∈ r tal que t₁[X] = t₂[X], se debe cumplir que t₁[Y] = t₂[Y].
-
DF son propiedad semántica de los atributos.
- Los diseñadores de las BD deben usar su entendimiento de la semántica para especificar las DF, y deben respetarse todos los
r(R). r(R)que satisface condiciones de DF se denomina instancia legal, estado legal o extensión legal de R.- No es posible determinar los DF de una relación a través de los valores de sus datos. Es necesario conocer el significado.
- Una DF puede existir si la cumple una instancia r(R)
- Para confirmar la existencia, es necesario conocer la semántica de los atributos.
- Para descartar la existencia, sólo basta con mostrar tuplas que violen esta posible DF.
- Un conjunto de DF se denota F.
- Una DF X⟹Y es completa si al eliminar algún atributo A de X la DF deja de existir. En caso contrario, es parcial.
- Horas depende de manera completa de PK
- E_Nombre depende de manera parcial de PK.
- P_Nombre y P_Ubicacion dependen de manera parcial de PK.
- Una DF X⟹Y es transitiva si existe un conjunto de atributos Z en R que no son ni CK ni un subconjunto de alguna clave de R, tal que X⟹Z y Z⟹Y.
- Una DF A⟹B es trivial si B⊆A.
- Por ejemplo, A⟹A es una DF trivial.
FN basadas en PK
- Se asume:
- Se cuenta con el conjunto DF para cada relación
- Cada relación tiene PK
- A cada esquema se le ejecutan test para certificar que satisfacen una forma normal.
- Objetivo:
- Minimizar redundancia
- Minimizar anomalías de actualización.
- Esquemas que no pasan ciertos tests, se descomponen en esquemas más pequeños.
- La forma normal de una relación se refiere a la mayor forma normal alcanzada por ella.
- No garantizan un buen diseño de la DB si se las considera aisladas de otros factores.
- Propiedades luego de la descomposición:
- Nonadditive Join (Lossless Join): no ocurre generación de tuplas espúreas; la relación original tiene que poder ser recuperada.
- Debe lograrse a cualquier costo.
- Preservación de DF: garantía de que cada DF se encuentra representada en algún esquema resultante de la descomposición.
- No siempre puede ser lograda; a veces se sacrifica.
- Nonadditive Join (Lossless Join): no ocurre generación de tuplas espúreas; la relación original tiene que poder ser recuperada.
Elementos
- Super Clave (SK): SK de
R = {A₁, ⋯, aₙ}es un subconjuntoS⊆Rde atributos tal quet₁,t₂ ∈ r(R) ∧ t₁ = t₂ ⟹ t₁(S) ≠ t₂(S). - Clave (K): una clave K es una SK con la propiedad adicional de que al remover cualquier atributo de K, deja de ser SK. Es decir, un SK minimal.
- Clave Candidata (CK): cada clave de un esquema se denomina clave candidata.
- Clave Primaria (PK): es una CK designada arbitrariamente como PK.
- Clave Secundaria: cualquier CK que no es PK.
- Atributo primo: atributo de un esquema R que pertenece a alguna CK de R.
- Requisito: todos los esquemas deben poseer PK en la práctica
1FN
- Prohibe: relaciones dentro de relaciones o relaciones como valores de atributos dentro de tuplas.
- Admite: El dominio de un atributo debe incluir valores atómicos (simples e indivisibles). En la tupla, puede tomar un solo valor del dominio.
Técnicas para alcanzar 1FN
DEPARTAMENTO
| D_NOMBRE | <D_NUMERO> | D_MGR_CUIL | D_AREAS_INFLUENCIA |
|---|---|---|---|
| Investigación | 2 | 27-233-9 | {Argentina, Brasil, Uruguay} |
| Prensa | 3 | 20-172-4 | {Chile} |
| Administración | 8 | 27-384-2 | {Argentina} |
-
Remover atributo que viola 1FN y ubicarlo en una nueva relación. La nueva relación tiene como PK ambos atributos.
-
Se mueve DPTO_AREAS_INFLUENCIA junto con la PK D_NUMERO.
DEPARTAMENTO
D_NOMBRE <D_NUMERO> D_MGR_CUIL Investigación 2 27-233-9 Prensa 3 20-172-4 Administración 8 27-384-2 DEPARTAMENTO_AREAS
<D_NUMERO> <D_AREAS_INFLUENCIA> 2 Argentina 2 Brasil 2 Uruguay 3 Chile 8 Argentina + Suele ser la mejor opción ya que no sufre de redundancia y es genérica (no se limita a un número de valores). 2. Expandir la PK que permita que exista más de un mismo D_NUMERO, pero con distinta área de influencia. + Esta solución introduce REDUNDANCIA en la relación. DEPARTAMENTO
D_NOMBRE <D_NUMERO> D_MGR_CUIL <D_AREAS_INFLUENCIA> Investigación 2 27-233-9 Argentina Investigación 2 27-233-9 Brasil Investigación 2 27-233-9 Uruguay Prensa 3 20-172-4 Chile Administración 8 27-384-2 Argentina 3. Si se conoce la cantidad máxima de valores que puede tomar el atributo, se pueden generar tantos atributos como esa cantidad. + Ejemplo, si hay 3 áreas de influencia como máximo por departamento. DEPARTAMENTO
D_NOMBRE <D_NUMERO> D_MGR_CUIL D_AREAS_INFLUENCIA1 D_AREAS_INFLUENCIA2 D_AREAS_INFLUENCIA3 Investigación 2 27-233-9 Argentina Brasil Uruguay Prensa 3 20-172-4 Chile NULL NULL Administración 8 27-384-2 Argentina NULL NULL -
Introduce valores NULL para los casos en que la tupla no posee todos los valores.
- No existe una semántica en cuanto al orden y ubicación de los valores.
- Consultas se vuelven más complejas.
- La técnica puede aplicarse recursivamente.
- Debe manejarse con cuidado cuando hay múltiples atributos multivaluados para no generar relaciones inexistentes.
-
Relaciones anidadas
Cuando el valor de una tupla es una relación.
-
1FN prohíbe relaciones anidadas.
- Mover atributos de relación anidada a una nueva relación
- Agregar a la nueva relación PK de la relación original
- PK de la nueva relación = clave parcial + PK relación original
-
Ejemplo:
EMP_PROY{<E_CUIL>, E_NOMBRE, PROYECTOS{<P_NUMERO>, HORAS}}se transforma enEMP{<E_CUIL>, E_NOMBRE}yEMP_PROY{<E_CUIL>, <P_NUMERO>, HORAS}.
2FN
Un esquema R está en 2FN si todo atributo no primo A de R depende funcionalmente de manera completa de la PK de R.
- Definición alternativa: Un esquema R está en 2FN si todo atributo no primo A de R depende completamente de todas las claves de R.
Tips - Verificar sólo DF cuyos lado izquierdo posean atributos que sean parte de la PK. - Si la PK es un solo atributo, cumple 2FN.
Ejemplo descomposición en 2FN: + EP1
E_DNI, P_NUMERO, HORAS
----- --------
v v ^
| | |
v-------v-------^
- EP2
E_DNI, E_NOMBRE
-----
v ^
| |
v-------^
- EP3
P_NUMERO, P_NOMBRE, P_UBICACION
--------
v ^ ^
| | |
v----------------------
3FN
Un esquema está en 3FN si está en 2FN, y además ningún atributo no primo de R depende transitivamente de la PK.
- Definición formal: Un esquema R está en 3FN si para toda dependencia funcional no trivial X⟹A de R, se cumple alguna de las condiciones:
- X es SK de R.
- A es atributo primo de R.
Ejemplo descomposición 3FN
- EMPLEADO_DEPARTAMENTO (es 2FN, pero no es 3FN)
E_NOMBRE | <E_CUIL> | E_FECHA_NACIMIENTO | NRO_DPTO | D_NOMBRE
^ v ^ ^ v ^
| | | | | |
^----------v--------------^--------------^ | |
| |
v---------^
- EMPLEADO
E_NOMBRE | <E_CUIL> | E_FECHA_NACIMIENTO | NRO_DPTO
^ v ^ ^
| | | |
^----------v--------------^---------------^
- DEPARTAMENTO
<NRO_DPTO> | D_NOMBRE
v ^
| |
v------------^
- El natural join ED1⋈ED2 de la descomposición recompone la relación original sin generar tuplas espúreas.
BCFN (Boyce-Codd Normal Form)
Un esquema R está en BCFN si pra toda dependencia funcional no trivial X⟹A de R, X es SK de R.
-
Es un derivado más restrictivo de 3FN, ya que no permite la condición de que A sea primo.
-
Reduce la redundancia.
- Se puede perder alguna DF.
Reglas de inferencia
El diseñador de la BD especifica DF semánticamente obvias. Existen DF no especificadas que pueden ser inferidas.
- R = {E_CUIL, NRO_DEPTO, D_NOMBRE}
- F = {E_CUIL ⟹ NRO_DEPTO, NRO_DEPTO ⟹ D_NOMBRE}
-
Usando ambas DF de F se puede deducir que E_CUIL ⟹ D_NOMBRE.
-
Una DF x⟹Y es inferida de o implicada por un conjunto de DFs F de R si se cumple X⟹Y en toda instancia legal r(R).
- Es decir, siempre que r(R) satisface F, se cumple X⟹Y.
- El conjunto de todas las DF de F más todas las DF que puedan ser inferidas de F se denota como F⁺.
- R = {E_CUIL, NRO_DEPTO, D_NOMBRE}
- F = {E_CUIL ⟹ NRO_DEPTO, NRO_DEPTO ⟹ D_NOMBRE}
- F⁺ = {E_CUIL ⟹ NRO_DEPTO, NRO_DEPTO ⟹ D_NOMBRE, E_CUIL ⟹ D_NOMBRE}
Axiomas de Armstrong
- RI1 (reflexiva): si
Y⊆X, entoncesX⟹Y. - RI2 (de incremento):
{X⟹Y} ⊧ XZ⟹YZ. - RI3 (transitiva):
{X⟹Y, Y⟹Z} ⊧ X⟹Z. - Propiedades:
- Fiable (Sound): dado F de R, cualquier DF deducida de F utilizando RI1, RI2 o RI3 se cumple en cualquier estado r(R) que satisface F.
- Completa (Complete): F⁺ puede ser determinado a partir de F aplicando solamente RI1, RI2 y RI3.
Corolarios de Armstrong (reglas adicionales)
- RI4 (de descomposición o proyección):
{X⟹YZ} ⊧ X⟹Y. - RI5 (de unión o aditiva):
{X⟹Y, X⟹Z} ⊧ X⟹YZ. - RI6 (pseudotransitiva):
{X⟹Y, WY⟹Z} ⊧ WX⟹Z.
Clausura
-
Diseño:
- Se especifica F el conjunto de DFs por semántica de atributos.
- Se utilizan RI1, RI2 y RI3 para inferir DFs adicionales.
- Determinar conjunto de atributos X que aparecen del lado izquierdo de cada DF de F.
- Determinar conjunto Y de atributos que dependen de X.
-
Clausura de X: conjunto de atributos que son determinados por X basados en F. Se denota X⁺.
Algoritmo para determinar X⁺
X⁺ := X
repetir
viejoX⁺ := X⁺
para cada DF Y⟹Z en F hacer
si Y⊆X⁺ entonces
X⁺ = X⁺∪Z
mientras(X⁺==viejoX⁺)
Clave de una relación
Búsqueda de una clave K en R a partir de un conjunto de DFs.
K := R
para cada atributo A∈K
calcular (K−A)⁺
si (K−A)⁺ contiene todos los atributos de R entonces
K := K − {A}
- Determina una sola de las CK, depende fuertemente de la manera en que son removidos los atributos.
Bibliografía
- Capítulo 15 (hasta 15.5 inclusive) Elmasri/Navathe - Fundamentals of Database Systems, 6th Ed., Pearson, 2011.
06. XML
Introducción
Datos estructurados
- Tienen un formato estricto
- Ejemplo: tablas
Datos semiestructurados
- Tienen una cierta estructura
- No todos los "registros" tienen la misma estructura
- La información sobre la estructura está mezclada con los datos
- Son "autodescriptivos"
- Se pueden representar como grafos
Datos no estructurados
- Sin estructura
- Ejemplo: XML
Formato XML
- XML: Extensible Markup Language
- Definido por la WC3
- Utilizado para el intercambio de datos
- Se puede extender por el usuario:
- Agregando nuevos tags y especificando cómo el tag debe ser manejado y mostrado.
- Los tags hacen que los datos sean autodocumentados.
Comparación con datos relacionales
- Ineficiente. Cada tag representa información del esquema, y estos se repiten en todo el archivo.
- Mejor para el intercambio de datos
- XML es autodocumentado
- El formato no es rígido: se pueden agregar nuevos tags
- Se permiten estructuras anidadas
- Amplia aceptación, no solo en bases de datos, sino en navegadores y aplicaciones.
TODO: Lo dejé acá porque es un embole esta diapo.
07. Open Data
Movimiento que apoya la difusión de datos por parte de los estados, organismos internacionales, empresas, etcétera.
-
Finalidades
- Open Goverment: Transparencia y parcicipación ciudadana.
- Mayor repercusión en América Latina.
- Generación de servicios para empresas y de valor para iniciativas privadas.
- Mayor repercusión en Europa.
- Open Goverment: Transparencia y parcicipación ciudadana.
-
Privacidad
- ¿Qué sabe la compañía celular de nosotros?
- Ley de acceso a la información pública
-
¿Quiénes consumen?
- Periodismo (ej: data driven journalism)
- ONGs (ej: chequeado.com)
- Emprendedores (ej: properati.com.ar/data)
- Académicos / estudiantes (ej: tesis)
09. noSQL
Conjunto muy variado de base de datos no relacionales que fueron diseñadas tomando en cuenta la existencia de datos no estructurados.
Características principales
- No relacionales.
- Distribuídas.
- Código abierto.
- Escalan horizontalmente.
Características generalmente aceptadas
- No tienen esquema (schema free)
- Tienen mecanismos sencillos de replicación
- Tienen interfaces sencillas
- Pueden almacenar grandes volúmenes de datos
- Cumplen con las propiedades BASE, no ACID
BASE
Basic Availability, Soft-state, Eventual consistency
- Basic Availability: garantiza la disponibilidad en términos del teorema CAP.
- Los datos deben estar disponibles, aún cuando se produzcan fallas.
- Esto se logra mediante el uso de una base de datos altamente distribuída.
- Se distribuyen los datos en muchos discos diferentes con un alto grado de replicación.
- Si sucede una falla que inhabilita el acceso a un grupo de datos, no afecta a toda la base de datos.
- Soft-state: el estado de la base de datos puede cambiar a lo largo del tiempo, aún sin intervención externa.
- Se aleja del requerimiento de consistencia de ACID que implica una única "versión" de cada dato.
- Esto se debe a la consistencia eventual.
- En BASE la consistencia es problema de los desarrolladores, y no debe ser administrada por las bases de datos.
- Eventual consistency: el sistema va a ser consistente a lo largo del tiempo, siempre que no se reciba más inputs.
- El único requisito en términos de consistencia es que los datos deben converger en algún momento del futuro a un único estado. No hay garantías de en qué momento ocurrirá eso.
Teorema CAP
Cualquier sistema que comparta datos a través de una red puede tener a lo sumo dos de las tres propiedades: consistencia (Consistency), alta disponibilidad (Availability), tolerancia a fallos/particiones (Partition tolerance).
- El objetivo de CAP hoy debería ser encontrar el balance entre consistencia y disponibilidad, estableciendo la forma de manejar las particiones y la manera en que se van a recuperar los errores que se produzcan durante las mismas.
Estrategia para las particiones
- Detectar la partición
- Entrar al modo "particionado"
- Recuperar del modo anterior
Estructura
En lugar de usar tablas, noSQL usa el concepto de almacenamientos del tipo clave/valor.
- No hay un schema.
- Al no tener esquema, pueden realizarse todo tipo de consultas complejas.
- Se almacenan los valores provistos para cada clave, y se los distribuye a lo largo de la base de datos.
- Esto permite una recuperación muy eficiente
Tipos de bases noSQL
- Desde KeyValue hacia Graph database disminuye el tamaño de los datos, pero aumenta la complejidad de los mismos.
1. Key-Value stores
La unidad atómica de modelado es el par clave-valor.
Características
- Es la más sencilla en cuanto a complejidad.
- Cada item es almacenado como un clave y su valor.
- Los datos pueden ser de distintos tipos: texto, XML, JSON, imágenes, etc.
- Son más adecuadas para la web o aplicaciones móviles.
- Están orientadas a items, y para cada item toda su información se almacena con su clave.
- Los items pueden almacenarse en "dominios", que son similares a las tablas.
- Los dominios no tienen schema, y pueden guardar items diferentes.
- Los items no tienen esquema, y pueden guardar objetos diferentes.
- Puede producir redundancia entre los items.
- Un par clave-valor perteneciente a un ítem A puede estar repetido en varios items B, C, D que de una forma u otra se vinculen con él.
- No existe integridad referencial (ni equivalente).
- Es decir, no hay nada que garantice que la relación entre dos tablas permanezca sincronizada durante operaciones de actualización y eliminación.
Ventajas
- Adecuadas para la nube
- Al ser simples y altamente distribuídas escalan mucho mejor que las relacionales
- Adecuadas para usar en OOP
Desventajas
- Integridad de datos y restricciones
- Al no existir mecanismos similares a los de BD relacionales para la definición de restricciones, todo queda en mano de los programadores.
- Limitaciones para el análisis
- Los datos carecen de estructura, por lo que para hacer un análisis de los mismos probablemente haya que pasarlos a una base donde se los pueda estructurar.
- Escalabilidad vs Funcionalidad y Complejidad
- A veces no tiene sentido poner la escalabilidad por delante de la funcionalidad.
2. Column Family databases
La unidad atómica de modelado es una familia de columnas.
Características
- Consisten en columnas de datos relacionados entre sí.
- Un grupo de columnas tiene función similar a las tablas relacionales.
- Son grupos de datos que, con frecuencia, son accedidos juntos.
- Proveen mecanismos naturales de partición vertical.
- Tienen almacenamiento multidimensional (como mapas o vectores asociativos).
Standard Column Family
Son pares clave-valor en donde el valor está representado por un conjunto de columnas.
Super Column Family
Son pares clave-valor en donde el valor está representado por un conjunto de conjunto de columnas.
- Haciendo una analogía con las bases relacionales, los valores serían similares a las vistas.
Ventajas
- Diseñadas para almacenar grandes volúmenes de datos
- Soport datos semi-estructurados
- Permite indexar los datos
- Es escalable y provee alta disponibilidad
Desventajas
- No son adecuadas para datos relacionales
- No proveen consistencia inmediata
3. Document stores
La unidad atómica de modelado es un documento.
Características
- Son similares a clave-valor, pero con diferencias que les permiten una mayor claridad en los datos en detrimento de la libertad.
- Los valores (documentos) pueden diferir entre sí en término de datos como de estructura.
- Se tiene metadata sobre los datos, lo que permite efectuar indexaciones sobre algunos campos.
Ventajas
- Mayor claridad en los datos que clave-valor.
- Se pueden hacer indexaciones y búsquedas eficientes.
Desventajas
- Se pierde libertad en comparación con clave-valor.
4. Graph databases
Modela toda la estructura como un grafo.
- Almacenan los datos como nodos conectados por medio de relaciones dirigidas y tipadas.
- Permite almacenar propiedades tanto en los nodos como en las relaciones.
Características
- Intuitivo
- Cumple ACID
- Escalable
- Alta disponibilidad
- Soporta lenguajes de consulta de grafos
- Puede ser accedido mediante servicios REST o una API orientada a objetos
-
Muchos problemas se representan naturalmente como grafos
-
Tanto SQL server como Oracle tienen en la actualidad funcionalidad de graph database.
Ventajas
TODO:?
Desventajas
TODO:?
PROS y CONS
| pros | cons |
|---|---|
| escalable | muchas opciones, por lo que resulta difícil elegir la base adecuada |
| esquema flexible | capacidad de query limitada |
| características distribuídas (confiable, escalable, recursos compartidos, velocidad) | consistencia eventual, hay entornos para el cual esto no es intuitivo (ej negocio bancario) |
| no tiene interrelaciones complicadas | no tiene joins, group by, order by, etc |
| menor costo por la facilidad de escalar en máquinas comunes | carece de ACID |
| open source | soporte limitado |
RDBMS vs noSQL
| Características | noSQL | RDBMS |
|---|---|---|
| Volumen | muchísimo volumen | volumen limitado |
| Validez de los datos | poca garantía | mucha garantía |
| Escalabilidad | horizontal | horizontal y vertical |
| Query Language | no tienen lenguaje | SQL |
| Schema | sin esquema o muy flexible | esquema rígido |
| Tipos de datos | no estructurado; no tiene límites | estructurado; han incorporado extensiones para permitir el almacenamiento de no estructurados |
| ACID/BASE | BASE (en general) | ACID |
| Administración de transacciones | garantía débil | garantía muy fuerte |
| Requerimientos de hardware | sin grandes requerimientos | servers propietarios, costosos |
Bibliografía / referencias
- http://nosql-database.org/
- http://www.couchbase.com/why-nosql/nosql-database
- http://www.linuxjournal.com/article/3294
- http://www.christof-strauch.de/nosqldbs.pdf
- http://databases.about.com
- http://www.analyticsvidhya.com/blog/2014/05/hadoop-simplified/
- https://www.usenix.org/legacy/events/lisa11/tech/slides/stonebraker.pdf 32
10. Data Warehousing
Business Intelligence
Término genérico que incluye aplicaciones, infraestructura, herramientas y prácticas que permiten el acceso y el análisis de la información para mejorar y optimizar las deciciones y el rendimiento.
Recursos
Fuentes de datos
-
Data warehouses: almacén de datos estructurado particularmente para su consulta y análisis.
- Data marts: son pequeños data warehouses que están centrados en un tema específico.
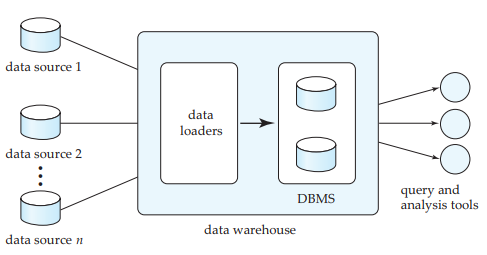
- Subject oriented: son datos orientados a temas específicos.
- Time-variant: los datos refieren a momentos particulares (snapshots).
- Non-volatile: siempre se agregan datos, no se quitan. Permiten análisis retrospectivos.
Comparación
Datos operacionales Data Warehouse Contenido Valores elementales Datos derivados Organización Por aplicación Por tema Estabilidad Dinámicos Estáticos Estructura Normalizada Desnormalizada Frec. Acceso Alta Media a baja Tipo acceso Lectura/Escritura Lectura Uso Predecible Ad hoc, heurístico Tiempo resp. Segundos Segundos a minutos #reg p/query < decenas Cientos a miles
Herramientas de administración de datos
TODO:
Herramientas de extracción y consulta
TODO:
Herramientas de modelización (data mining)
TODO:
14. Schedules
Transacción
Una transacción es una colección de operaciones que deben aplicarse de forma atómica en una base de datos. Esta atomicidad, además aplica a la consistencia (las restricciones de la base), es decir que si una base de datos era consistente antes de una transacción, debe seguir siéndolo luego de aplicar la misma. La base puede volverse, sin embargo, inconsistente de forma temporal durante la aplicación de las operaciones internas de la transacción.
- Toda transacción termina, o bien con un ABORT (y su respectivo rollback), o bien con un COMMIT.
Propiedades ACID
Propiedades que debe cumplir una transacción.
- Atomicidad: O bien todas las operaciones son aplicadas apropiadamente en la base de datos, o bien ninguna lo es.
- Consistencia (integridad): La ejecución de una transacción preserva la consistencia de una base de datos.
- Isolación (aislamiento): Una transacción no puede afectar a otra. Cada transacción es independiente de otras transacciones ejecutándose concurrentemente en el sistema.
- Durabilidad (persistencia): Los cambios son correctamente persistidos una vez que la transacción termina, y no se podrá deshacer incluso ante una falla del sistema.
Historia
Una historia es un orden en que se ejecuta un conjunto de transacciones en donde se respeta el orden parcial de cada transacción.
-
Conflictos entre operaciones cuando:
- Pertenecen a historias distintas
- Operan sobre un mismo data item
- Al menos una de ellas es un write
-
Dos historias H1, H2 son conflicto-equivalente si se puede llegar desde H1 hasta H2 a través de swaps de operaciones consecutivas que no se encuentren en conflicto.
Serialización
Una historia es conflicto-serializable cuando es conflicto-equivalente a una versión serial de la misma.
Ejemplo, si se tienen las siguientes transacciones: - T1 = (T1a, T1b, T1c) - T2 = (T2a, T2b) - T3 = (T3a)
Y las siguientes historias:
-
H1 = (T1a, T2a, T1b, T3a, T1c, T2b)
T1 T2 T3 T1a T2a T1b T3a T1c T2b -
H2 = (T1, T2, T3)
T1 T2 T3 T1a T1b T1c T2a T2b T3a
H1 es conflicto-serializable si es conflicto-equivalente a H2, es decir, si los swaps necesarios para llegar de una a otra son no conflictivos.
Tipos de historia
- Recuperable (RC): Tᵢ lee de Tⱼ en H y cᵢ ∈ H ⟹ cⱼ < cᵢ
- Evita abort en cascada (ACA): Tᵢ lee x de Tⱼ en H ⟹ cⱼ < rᵢ(x).
- Estricta (ST): wⱼ(x) < oᵢ(x) ⟹ aⱼ < oᵢ(x), o cⱼ < oᵢ(x). (cuando hay una operación de escritura de la historia j sobre x que se encuentra antes que una operación de la historia i sobre x, entonces o bien hay un abort de j sobre x o bien hay un commit de j, y en todo caso se encuentra antes de la operación de la historia i sobre x).
15. Control de Concurrencia
Problemas básicos
-
Tres problemas básicos
- Modificación perdida
- Falsa sumarización
- Falsa modificación (dirty read)
-
Decisiones del scheduler frente a una operación:
- Rechazarla
- Procesarla
- Demorarla
-
Scheduler agresivo: favorece el procesamiento de la operación
- Scheduler conservador: favorece el rechazo o la demora de las operaciones.
Lock binario
Utiliza el concepto de Lock/Unlock asociado a una variable.
-
La variable tiene dos estados (locked, unlocked).
-
Notación:
- lᵢ(X): Tᵢ lockea el item X
- uᵢ(X): Tᵢ libera el item X
-
Cuando una transacción lee o escribe un ítem, antes solicita un lock sobre el mismo.
Shared lock (lock ternario)
Extensión del lock binario, permite que el lock sea exclusivo o compartido
- Notación:
- rlᵢ(X): Tᵢ lockea X - compartido
- "Read Lock"
- wlᵢ(X): Tᵢ lockea X - exclusivo
- "Write Lock"
- ulᵢ(X): Tᵢ actualiza el lock de X, de compartido a exclusivo
- "Read Lock" ⟹ "Write Lock"
- rlᵢ(X): Tᵢ lockea X - compartido
Two Phase Locking (2PL)
Protocolo que asegura la serialización. Requiere que cada transacción emita los pedidos de lock y unlock en dos fases.
- Fases del Two Phase Lock:
- Growing phase (fase de crecimiento): una transacción puede pedir locks, pero no puede liberar locks.
- Shrinking phase (fase de decrecimiento): una transacción puede liberar locks, pero no puede obtener nuevos locks
- Inicialmente, una transacción está en la fase de crecimiento, y puede pedir locks.
- A partir del punto en que libera algún lock, ya no puede volver a pedir más locks.
- Peligro: se pueden generar deadlocks.
Deadlocks
Wait-For Graph (WFG)
Grafo que representa qué operaciones esperan de otras.
- Un nodo por cada transacción.
- Hay un arco entre dos nodos cuando una transacción está esperando a otra.
- Hay deadlock si se forma un ciclo.
Ejemplo WFG sin deadlock
--> T2 ---> T4
/ ∧
/ |
T1 |
\ |
\ |
--> T3
Ejemplo WFG con deadlock (T2->T4->T3->T2)
--> T2 -----> T4
/ ∧ /
/ | /
T1 | /
\ | /
\ | /
--> T3 <--
Recuperación
Cuando se detecta un deadlock, se debe solucionar mediante una operación de recuperación.
- La solución más común es hacer un rollback (deshacer las operaciones) de una o más de las transaciones involucradas.
- Para hacer un rollback se deben tener en cuenta tres cosas:
- Elegir una víctima: idealmente, deben elegirse deshacer las transacciones de tal forma que esto involucre un costo mínimo. Este costo es difícil de encontrar, y se tienen en cuenta entre otras cosas:
- Cuántas operaciones lleva computadas la transacción, y cuántas le faltan para terminar.
- Cuántos items de datos usó la transacción.
- Cuántos items de datos le falta usar a la transacción para terminar.
- Cuántas transacciones serán afectadas por el rollback.
- Realizar el rollback.
- Lo más simple es hacer un rollback total volviendo todo al estado original antes de realizar la transacción.
- Existen soluciones como rollback parcial que requieren que el sistema mantenga información adicional (por ejemplo los distintos estados antes de pedir cada lock).
- Debe evitarse el starvation de una transacción.
- Por ejemplo, si una transacción es muy pesada, esta puede terminar siempre siendo elegida para hacer rollback, con lo cual nunca se ejecuta.
- Una forma de evitar esto, es llevando un conteo de la cantidad de veces que fue rollbackeada cada transacción, y haciendo que este número forme parte de la función de costo a la hora de elegir la víctima.
- Elegir una víctima: idealmente, deben elegirse deshacer las transacciones de tal forma que esto involucre un costo mínimo. Este costo es difícil de encontrar, y se tienen en cuenta entre otras cosas:
Timestamps
Se asocia un timestamp único a cada transacción, denotado TS(Tᵢ).
-
Las dos formas comunes de implementar esto son:
- Usando el system clock.
- Usando un contador que es incrementado atómicamente cada vez que un timestamp se asigna.
-
Los timestamp de las transacciones determinan el orden de serialiación.
- Esto significa que si TS(Tᵢ) < TS(Tⱼ) entonces el planificador debe producir una historia que sea equivalente a una serialización en donde Tᵢ aparezca antes que Tⱼ.
-
Para implementar esto, se asigna a cada data item dos timestamps:
- W-timestamp(Q) denota el mayor timestamp de cualquier transacción que haya ejecutado write(Q) correctamente.
- R-timestamp(Q) denota el mayor timestamp de cualquier transacción que haya ejecutado read(Q) correctamente.
Timestamps - Protocolo de ordenamiento
Asegura que cualquier operación de lectura o escritura conflictiva se ejecute en el orden indicado por el timestamp.
- Lectura
- Si TS(Tᵢ) < W-timestamp(Q): Tᵢ necesita leer un dato en Q que ya fue sobre-escrito. Se rechaza la operación, y se hace rollback a Tᵢ.
- Si TS(Tᵢ) ≥ W-timestamp(Q): la operación es ejecutada, y el R-timestamp(Q) es actualizado a max(R-timestamp(Q), TS(Tᵢ)).
- Escritura
- Si TS(Tᵢ) < R-timestamp(Q): el valor de Q que Tᵢ está por escribir fue necesitado previamente en una lectura. Como no se puede escribir "hacia el pasado", se rechaza la operación y se hace rollback a Tᵢ.
- Si TS(Tᵢ) < W-timestamp(Q): el valor de Q que Tᵢ está por escribir ya fue escrito por un valor más nuevo, por lo que el valor que se está intentado escribir es obsoleto. Se rechaza la operación y se hace rollback a Tᵢ.
- Notar que este caso es posteriormente abordado por la Thomas Write Rule.
- en cualquier otro caso: la operación es ejecutada, y el W-timestamp(Q) es actualizado a TS(Tᵢ).
Thomas Write Rule
Modificación del protocolo de ordenamiento para timestamps que permite descartar operaciones write obsoletas (cuando el valor que tiene X es más nuevo al que se quiere escribir).
- Esto permite a veces ejecutar historias que no son conflicto-serializables, pero sí son view-serializable, eliminando las operaciones conflictivas.
- Notar que para que una escritura entre en el caso descrito previamente, esta debe ser un blind write, es decir, una escritura que no requirió una lectura previa. De lo contrario, a pesar de que se cumpliría TS(Tᵢ) < W-timestamp(Q) (con lo cual se podría ignorar el write), también se cumpliría Si TS(Tᵢ) < R-timestamp(Q), lo cual haría que se rollbackeara la operación de todos modos.
- Esto permite descartar w1(x) en una historia como:
w2(x)w1(x), pero no en una historia comor2(x)w2(x)w1(x), ya que en este último caso podría ser que al haber leído la variable, el valor guardado en w2(x) dependa del valor leído en r2(x) (que a su vez depende de w1(x)).
- Esto permite descartar w1(x) en una historia como:
Multiversión
Se guardan distintas versiones de los datos, una por cada transacción vigente.
-
Cada versión Qₖ contiene tres datos:
- Contenido: el valor de la versión Qₖ
- W-timestamp(Qₖ): timestamp de la transacción que creó la versión.
- R-timestamp(Qₖ): mayor timestamp de las transacciones que leyeron Qₖ.
-
Si una transacción Tᵢ quiere hacer una operación, sea Qₖ la versión cuyo timestamp es el mayor tal que sea menor i igual a TS(Tᵢ).
- Si la operación es read(Q), entonces el valor retornado es Qₖ.
- Si la operación es write(Q)
- si TS(Tᵢ) < R-timestamp(Qₖ), entonces el sistema rollbackea la transacción
- si TS(Tᵢ) ≥ R-timestamp(Qₖ) y TS(Tᵢ) = W-timestamp(Qₖ), se sobreescriben los valores de Qₖ
- si TS(Tᵢ) > R-timestamp(Qₖ) se crea una nueva versión de Q.
Multiversión con Two Phase Lock
Se puede combinar multiversionado con Two Phase lock, obteniendo las ventajas de ambos protocolos.
- Las transacciones se diferencian entre transacciones de read y transacciones de write.
- Se utiliza un contador atómico ts-counter que se actualiza con cada commit.
- Las transacciones de read se setean con un timestamp igual a _ts-counter)
- Las transaciones de update inicialmente setean los nuevos datos poniendo un timestamp infinito.
- Cuando la transacción se commitea, guarda el timestamp correspondiente (ts-counter+1), aumentando asimismo dicho contador en 1.
- La etapa de commit tiene un lock de forma tal que no pueden haber más de una operación realizando commit a la vez.
- Si Tᵢ realiza un read(Q), entonces el valor es retornado inmediatamente, y es el contenido de la versión Qₖ.
Niveles de aislamiento (SQL)
Fenómenos que violan el aislamiento (y la serialización)
- Lost Updates: se pierde un write, ya que se pisa posteriormente con un valor que debería haber sido escrito antes.
- Dirty Read: se lee un valor escrito por una transacción que todavía no commiteó.
- Nonrepeatable Read: una transacción lee el mismo dato dos veces, y encuentra un valor distinto la segunda vez a pesar de no haber hecho ninguna escritura a ese dato.
- Phantom Read: una transacción commitea una nueva tupla, que puede o no ser usada por una lectura concurrente.
Comparación
| Isolated level | Lost Updates | Dirty Read | Non repeat. Read | Phantom Read |
|---|---|---|---|---|
| Read Uncommitted | No | Maybe | Maybe | Maybe |
| Read Committed | No | No | Maybe | Maybe |
| Repeated Read | No | No | No | Maybe |
| Serializable | No | No | No | No |
16. Logging
Existen 3 tipos de fallas:
- de transacciones
- de sistema
- de almacenamiento
Estas fallas tienen que ver con pérdida de datos en memoria.
TODO: este tema es un embole, lo voy a saltear por ahora
17. Long Duration Transactions
- Existen transacciones que pueden durar o insumir mucho más tiempo o cómputo de lo normal.
- Transacciones que afecten a una cantidad inmensa de registros.
- No es razonable bloquear la base durante 2 días.
- No es razonable la cantidad de información que hay que almacenar para hacer rollback en caso de que se use algún mecanismo de control de concurrencia de los mencionados previamente.
- Sistemas de workflow, es decir en donde haya un flujo de trabajo en el que se vean involucrado varios procesos Pᵢ distintos, y en donde estos formen una cadena [P₁ ⟹ P₂ ⟹ ⋯ ⟹ Pₙ], en donde el resultado de cada proceso dependa del proceso anterior.
- No es posible utilizar los mecanismos de control de concurrencia habituales.
- Transacciones que afecten a una cantidad inmensa de registros.
Sagas
Una saga es un conjunto de acciones [A₁ ⟹ A₂ ⟹ ⋯ ⟹ Aₙ] que conforman un long duration transaction.
-
Una saga se compone de:
- Una colección de acciones.
- Un grafo dirigido en donde los nodos son, o bien acciones, o bien un nodo terminal del tipo ABORT o COMPLETE.
- Ningún arco parte desde un nodo terminal.
- Alguno de los nodos del grafo se denota como nodo inicial.
-
Los caminos en el grafo de una saga representan secuencias de acciones.
-
El control de concurrencia de la saga se realiza en dos partes
- Cada acción se considera en sí misma como una pequeña transacción.
- La sucesión de acciones se maneja con el mecanismo de transacciones compensatorias, que son acciones inversas a cada uno de los nodos de la saga.
Acciones compensatorias
Sea A una acción, la acción de compensación A⁻¹ es tal que si se tiene una base en un estado S, al aplicarle A y luego A⁻¹ se vuelve a obtener el mismo estado S inicial.
- Más aún, aplicar la secuencia de acciones ABA⁻¹ equivale a aplicar la acción B.
- Esto significa que si se tiene una secuencia de acciones correspondientes a una saga:
[A₁, A₂, ⋯, Aₙ]y se aplican en ese orden sobre una base, generando un ABORT enAᵢcon0>i≤n, se deben aplicar las acciones de compensación en el orden inverso, es decir[Aᵢ⁻¹, ⋯, A₂⁻¹, A₁⁻¹].- Si suponemos que todas estas acciones se intercalan con otras acciones B₁, B₂, etc, en donde cada Bᵢ es un conjunto de operaciones correspondientes a otras transacciones, la secuencia resultante
[A₁, B₁, A₂, B₂, ⋯, Bᵢ Aᵢ, Aᵢ⁻¹, Bᵢ₊₁, ⋯, Bⱼ, A₂⁻¹, Bⱼ₊₁, A₁⁻¹]termina siendo equivalente a haber aplicado todas las acciones B sin haber aplicado las acciones A, es decir[B₁, B₂, ⋯, Bᵢ, Bᵢ₊₁, ⋯, Bⱼ, Bⱼ₊₁], lo cual significa que se mantiene la consistencia de la base.
- Si suponemos que todas estas acciones se intercalan con otras acciones B₁, B₂, etc, en donde cada Bᵢ es un conjunto de operaciones correspondientes a otras transacciones, la secuencia resultante
18. In-Memory databases
Una "in-memory database" es una base de datos que carga toda la base en memoria.
Tipos
- Sin persistencia
- Cuando se apaga la computadora, se pierden todos los datos.
- Ej: Membase, Varnish, etc
- Con persistencia
- Los datos además se persisten a disco
- Ej: Redis, Sap Hanna, etc
Persistencia
- Todas las interacciones con la DB se resuelven en memoria
- Se escribe constantemente en un log de transacciones
- Como las escrituras al log se realizan secuencialmente, es muy rápido
Almacenamiento
- Por columnas o por filas
- Las operaciones de agregación se benefician del almacenamiento "por columnas".
19. Distributed Databases
Una base de datos distribuída es una colección de múltiples bases de datos que están lógicamente relacionadas y se encuentran distribuídas en una red de computadoras.
Condiciones que debe satisfacer: - Interconexión entre BDs. - Relación lógica entre BDs interconectadas. - Heterogeneidad entre nodos.
Interconexión
- Tipo: LAN, WAN, etc
- Topología: "caminos" de comunicación, formas en que se conecta.
- Todo esto impacta en la estrategia y el diseño de la DDB
Transparencia
Ocultar detalles de implementación a usuarios finales
- BD Centralizadas
- Independencia entre datos físicos y lógicos
- BD Distribuídas: nuevos tipos de transparencia
- Organización de los datos
- Fragentación
- Replicación
- Otras
Organización de los datos
(también distribución u organización de red)
- Libera al usuario de conocer los detalles de red y ubicación de datos
- Se divide en:
- Transparencia de ubicación: el comando utilizado para realizar una tarea no es afectado por la ubicación de los datos, ni tampoco por desde dónde se lanza el mismo.
- Transparencia de nombres: una vez asociado un nombre a un objeto, este puede ser accedido de manera unívoca desde cualquier ubicación, sin requerir datos adicionales.
Fragentación
- Libera al usuario de conocer detalles de fragmentación de los datos.
- Se divide en:
- Horizontal (sharding): distribuye la relación (tabla) en subrelaciones que son subconjuntos de las tuplas (filas) de la relación original
- Para reconstruir una relación que fue fragmentada horizontalmente se debe aplicar UNION a todos los fragmentos
- Vertical: distribuye la relación en subrelaciones donde cada subrelación es definida por un subconjnto de columnas de la relación original
- Para reconstruir una relación que fue fragmentada verticalmente se debe aplicar JOIN a los fragmentos.
- Mixta: distribuye la relación en subrelaciones que son una mezcla de fragmentación vertical y horizontal.
- Horizontal (sharding): distribuye la relación (tabla) en subrelaciones que son subconjuntos de las tuplas (filas) de la relación original
- En ambos casos el usuario desconoce la existencia de fragmentos
Replicación
- Libera al usuario de conocer la existencia de copias de los datos.
- Los objetos pueden ser almacenados en varios sitios simultáneamente para mejorar disponibilidad, performance, confiabilidad.
Otras
- Diseño: libera al usuario de conocer cómo está diseñada la DDB
- Ejecución: libera al usuario de conocer dónde o cómo es ejecutada una transacción
Disponibilidad y Confiabilidad
- Disponibilidad: probabilidad de que un sistema se encuentre contínuamente disponible en un intervalo de tiempo.
-
Confiabilidad: probabilidad de que un sistema se encuentre operando en un momento determinado de tiempo.
-
Fallos asociados:
- Failure (fallo): desviación del comportamiento esperado del sistema
- Errores: subconjunto de estados del sistema que causan failures
- Fault (falla): causa de un error
-
Para construir un sistema confiable
- Stresses fault tolerance: reconocer fallos, detectarlos y removerlos previos a que ocurran
- Alternativa: asegurar que el sistema no tenga faults, siguiendo procesos de desarrollo que tengan QA y testing
-
Un DDBMS debe tolerar fallos de componentes subyacentes sin alterar el procesamiento de pedidos ni la consistencia de la DB.
-
Recovery Manager: componente que trata con los fallos.
- Disponibilidad y confiabilidad se usan indistintamente en DDB.
Escalabilidad y Particiones
- Escalabilidad determina la medida en que el sistema puede expandirse
- Horizontal: expandir la cantidad de nodos
- Vertical: expandir la capacidad individual de los nodos
- La tolerancia a partición o a falla es la capacidad de continuar operando a pesar de que la red sea particionada (nodos o mensajes retrasados o descartados). Es uno de los componentes del teorema CAP (Consistency, Availability, Partition Tolerance).
Autonomía
Determina en qué medida los nodos individuales pueden operar independientemente
- Es deseable un alto grado de autonomía.
- Diseño: independencia del modelo entre los nodos
- Comunicación: en qué medida los nodos pueden compartir o no información
- Ejecución: que los usuarios puedan realizar todo tipo de acciones
Ventajas
- Mejora el desarrollo de aplicaciones: se pueden mantener aplicaciones en sitios geográficamente distribuídos debido a la transparencia de control y distribución de datos
- Aumento de la disponibilidad: los fallos son aislados a su nodo, sin afectar a otros nodos
- Mejora de la performance: debido a la fragmentación horizontal
- Escalabilidad: agregar más datos (vertical) o agregar nodos (horizontal).
Transparencia total
Provee al usuario una visión de la DDB como si fuera un sistema centralizado.
- Hay un tradeoff entre facilidad de uso y costo de proveer la transparencia.
Esquemas de fragmentación
- Incluye a todos los atributos y tuplas de la DB fragmentada
- La totalidad de la BD puede ser construida a partir de fragmentos aplicando operaciones (union o join + union)
- Es útil (pero no necesario) que los fragmentos sean disjuntos (excepto por la PK)
- Esquema de asignación describe la ubicación de los fragmentos en los nodos
- Si un fragmento está en más de un lugar, está replicado
Replicación total
- Objetivo tener mayor disponibilidad de datos
- Ventajas
- Se continúa operando mientras haya al menos un nodo disponible
- Mejora la performance de lecturas
- Desventajas
- Baja performance de escritura (debe realizarse en todas lsa copias)
- Las técnicas de control de concurrencia y recuperación son más costosas
Replicación parcial
- Algunos fragmentos se replican, otros no.
- Un esquema de replicación es una descripción de los esquemas de la DDB.
- Cada fragmento debe ser asignado a un sitio particular, esto se denomina distribución de datos.
- La elección de sitios y el grado de replicación depende de:
- Metas de disponibilidad
- Metas de performance
- Tipo de transacciones realizadas
Control de concurrencia y Recovery
Ambientes distribuídos traen nuevos problemas.
- Tratar con múltiples copias de un data item
- CC: mantener consistencia entre copias
- Recovery: realizar copia consistente con otras copias si falla el nodo
- El DDB debe continuar operando ante fallas
- Nodo: cuando se recupera, debe ser actualizada con respecto a otros sitios
- Fallas de comunicación: caso extremo partición de la red.
- Commit distribuído: cómo resolver si un nodo falla durante commit.
- Deadlock distribuído: cómo resolver un deadlock entre nodos.
Control de Concurrencia
Responsable de mantener consistencia entre copias
- Locking: designar una copia de cada sitio como distinguida.
- Sitio primario: todas las copias distinguidas se mantienen en un único sitio
- Si T obtiene rlock(X) de sitio primario, puede acceder a cualquier copia de X
- Si T obtiene wlock(X) de sitio primaria y actualiza X, el DDBMS es responsable de actualizar todas las copias de X antes de realizar unlock(X)
- Two-phase Commit: si todas las T siguen protocolo 2PC, la seriabilidad está garantizada
- Ventaja: simple, extiende al enfoque centralizado
- Desventajas:
- Performance: Cuello de botella en el sitio primario.
- Disponibilidad: Single Point of failure, si falla el sitio primario, falla todo.
- Sitio primario con sitio de backup:
- El backup intenta solucionar desventaja de disponibilidad (2).
- La información de los locks se mantiene en ambos sitios.
- En caso de falla del Nodo Primario, Nodo Backup toma el control.
- Ventaja: simplifica el proceso de recovery ante falla de Nodo Primario
- Desventajas:
- Persiste cuello de botella
- Disminuye más performance en procesos de lock (por copia a sitio backup)
- Copia primaria:
- Intenta solucionar problema de performance (cuello de botella)
- Admite copias distinguidas en diferentes sitios
- Falla de un nodo sólo afecta a T con locks en data items cuya copia primaria se encuentra en dicho nodo.
- Pueden agregarse nodos de backups para aumentar disponibilidad.
- Sitio primario: todas las copias distinguidas se mantienen en un único sitio
Falla de Nodo Primario - Eleccion de nuevo coordinador
- Sitio primario: todas las T deben ser abortadas y reiniciadas
-
Con backup: las T se suspenden mientras se designa al backup como nuevo primario
-
Si fallan primario y backup: Proceso de elección (algoritmo complejo)
- Si sitio Y intenta comunicarse con coordinador y no puede, asume que el coordinador falló y puede iniciar proceso de elección
- Envía a todos los nodos activos que Y va a ser el nuevo coordinador
- Si Y recibe mayoría de votos afirmativos, Y se declara coordinador
- También se debe resolver intentos de dos o más sitios intentando ser coordinadores simultáneamente.
Falla de Nodo Primario - Votación
- Se hace un pedido de lock(X) a todos los sitios que tienen una copia de X
- Cada copia de X es responsable de su propio lock, y puede aceptar o denegar
-
Si T pide lock(X)
- Si recibe OK de la mayoría de las copias, toma el lock y avisa a todas las copias que lo tomó
- Si NO recibe el ok de la mayoría dentro de un período de timeout, cancela el pedido e informa a todos de la cancelación
-
Ventaja: es considerado un método de control de concurrencia realmente distribuído (la decisión reside en los nodos)
- Desventajas:
- Mayor tráfico de mensajes
- El algoritmo es muy complejo, tiene que tener en cuenta cosas como la caída de nodos durante la votación
Recovery - Problemas
- Fallos en sitios y comunicaciones
- En ciertos casos es muy difícil determinar cuándo un sitio se encuentra caído.
- Ejemplo: sitio X envía un mensaje a sitio Y, del cual espera una respuesta. Posibles causas:
- Nunca llegó mensaje a Y por problema en comunicación
- Y está caído
- Y se encuentra funcionando y envía respuesta, pero no llegó por problema en comunicación
- Ejemplo: sitio X envía un mensaje a sitio Y, del cual espera una respuesta. Posibles causas:
- En cualquier caso, también es complicado determinar la causa.
- En ciertos casos es muy difícil determinar cuándo un sitio se encuentra caído.
- Commit distribuído
- Si T actualiza información en varios sitios, no puede terminar el COMMIT hasta asegurarse de que los efectos de T no se van a perder en ningún sitio (grabación de log)
- Es frecuente usar 2PC para asegurar correctitud de commit distribuído
Transacciones
Propiedades ACID
Propiedades que debe cumplir una transacción.
- Atomicidad: O bien todas las operaciones son aplicadas apropiadamente en la base de datos, o bien ninguna lo es.
- Consistencia (integridad): La ejecución de una transacción preserva la consistencia de una base de datos.
- Isolación (aislamiento): Una transacción no puede afectar a otra. Cada transacción es independiente de otras transacciones ejecutándose concurrentemente en el sistema.
- Durabilidad (persistencia): Los cambios son correctamente persistidos una vez que la transacción termina, y no se podrá deshacer incluso ante una falla del sistema.
2PC
- Problema: protocolo de bloqueo. Si falla el coordinador una vez pedido el lock, bloquea a todos los nodos participantes.
3PC
Divide segunda fase de commit en dos subfases.
- Prepare to commit
- Comunica resultado de la fase de votación a todos los participantes
- El commit se debe preparar en esta fase
- Si todos los participantes votan afirmativamente, pide que pasen a prepare-to-commit
-
Commit
- Idéntico a commit en 2PC
- Si el coordinador cae durante esta subfase, otro participante puede tomar asumir la coordinación del commit.
- Se limita el tiempo requerido por T para realizar el commit, ya que se preparó en la fase anterior, por lo que solo debe ser aplicado. Esto asegura liberar los locks luego de un determinado tiempo.
-
Tiene algunas desventajas, principalmente el overhead para asegurarse de que no hayan inconsistencias, por lo que no ampliamente muy usado debido a problemas de red (muchos nodos fallando a la vez).
Queries distribuídos
- Mapeo: se mapea la consulta SQL a una consulta de AR sobre las relaciones globales, referenciando al esquema global.
- NO se utiliza la información de distribución y replicación.
- El mapeo es idéntico al de las BD centralizadas: normalización, análisis de errores, simplificación, reestructuración.
- Localización: se mapea el resultado anterior a múltiples consultas sobre fragmentos individuales.
- Se utiliza la información de distribución y replicación.
- Optimización global: se selecciona una estrategia de una lista de candidatos cercanos al óptimo.
- Tiempo es la unidad más utilizada para medir costo
- Costo total es ponderado entre CPU, I/O, comunicación/red.
- Costo de comunicación/red suele ser muy significativo.
- Optimización local: similar a las BD centralizadas, se optimiza cada query localmente.
Queries - Costos
- Problema: alto costo de transferencia sobre la red
- Solución: los algoritmos de optimización deben considerar reducir la cantidad de datos a transferir.
Queries - Semijoin
Reducir cantidad de tuplas de una relación antes de que sean transferidas a otro nodo.
-
Implementación:
- enviar sólo columna de JOIN
- realizar JOIN
- del resultado retornar columna de join + atributos necesarios
- completar consulta
-
Ventaja: si solo una pequeña fracción de la relación participa en el JOIN, reduce mucho la transferencia de datos.
Tipos de DDB
-
Definición: Datos y sotware distribuídos en múltiples lugares, pero conectados a través de una red.
-
Grado de homogeneidad:
- Homogéneo: si todos los servers y usuario utilizan el mismo software
- Heterogéneo: si usan distinto software
- Es necesario un lenguaje canónico y un traductor que haga de intermediario al lenguaje de cada uno de los servers.
- Grado de autonomía local:
- Si se le permite al sitio funcionar como DBMS standalone o no
- (ver arriba: autonomía de diseño, comunicación y ejecución).
- Ejemplo: FDBS y p2pDBS: cada server es un DBMS independiente y autónomo que tiene sus propios usuarios, transacciones, DBA, y por lo tanto alto grado de autonomía.
- p2pBS: no hay esquema global, se construye a medida que se requiere
- FDBS: existe un esquema global federado
- Si se le permite al sitio funcionar como DBMS standalone o no
Federated Databases - Heterogeneidad
-
Origen
- Diferencias en modelo de datos: DBs pueden venir de distintos modelos.
- Se requiere un mecanismo que procese las queries y relacione la información basado en metadata.
- Diferencias en restricciones: varían de sistema en sistema.
- Se debe lidiar con conflictos en restricciones (integridad, triggers, etc).
- Diferencias en lenguajes: incluso dentro del mismo modelo, los lenguajes poseen varias versiones.
- Ejemplo: SQL-89, SQL-92, SQL-99, SQL-2008.
- Diferencias en modelo de datos: DBs pueden venir de distintos modelos.
-
Heterogeneidad semántica: ocurre cuando existen diferencias en el significado, interpretación y uso de los datos.
- Las DBS tienen autonomía de diseño y pueden tomar decisiones.
-
Solución actual: utilizar software responsable de administrar queries y transacciones desde la aplicación global hacia las DBs individuales (pudiendo incorporar reglas de negocio).
- Middleware
- Application servers
- Enterprise Resource Planning (ERP)
- Modelos y herramintas para Data Integration y Data Exchange: para hacer integración y mapeo en un lenguaje de alto nivel.
- Ontology-based Data Access/Query: modelo de más alto nivel que el relacional.
- El acceso a los datos se hace mediante un lenguaje ontológico de fácil acceso para el usuario (sin entendimiento de BBDD).
Federated Databases - Autonomía
- Comunicación: capacidad de decidir cuándo comunicarse con otras DBs
- Ejecución: capacidad para ejecutar operaciones locales sin interferir en operaciones externas, y también capacidad de decidir el orden
- Asociación: capacidad de decidir si compartir y cuánto compartir
- Funcionalidad: operaciones que soporta
- Recursos: datos que gestiona
Arquitecturas Paralelas vs Distribuídas
- Prevalencia en industria: ambas
- Paralela común en HPC
- Distribuída común en grandes empresas
- Arquitecturas de sistema multiprocesador: se desarrollan Parallel Database Management Systems (PDBMS)
- Red: no requieren compartir red
- Memoria compartida: comparten memoria y disco
- Disco compartido: comparten disco, pero cada uno tiene memoria propia
- Shared-nothing: cada procesador posee su propia memoria y su propio disco
Catálogo distribuído
El catálogo es una BD en sí misma
- Contiene metadata acerca del DDBMS
- Administración
- Autonomía
- Vistas
- Distribución y replicación de datos
- Esquemas de administración
- Centralizado: el catálogo completo se almacena en un único sitio
- Ventaja: simple de implementar
- Desventajas:
- Poca confiabilidad
- Poca disponiilidad
- Poca autonomía de los nodos
- Poca distribución de la carga de procesamiento
- Los locks generan cuellos de botella cuando hay escrituras intensivas
- Totalmente replicado: cada sitio almacena una copia del catálogo completo
- Ventaja: lecturas pueden responderse localmente
- Desventajas:
- Overhead: actualizaciones deben ser transmitidas a todos los nodos
- Esquema centralizado de 2PC para mantener consistencia del catálogo
- Aplicaciones escritura-intensivas (con locks) pueden incrementar el tráfico de la red
- Parcialmente replicado: cada sitio mantiene información completa del catálogo de los datos locales
- Cada sitio permite almacenar en caché entradas obtenidas de otros sitios
- Entradas en cache no garantiza información actualizada
- Cada sistema lleva registro de las entradas del catálogo para los sitios donde se creó el objeto, y para los sitios que tienen copias del objeto
- Cualquier cambio debe ser propagado al sitio original (de creación).
- Cada sitio permite almacenar en caché entradas obtenidas de otros sitios
- Centralizado: el catálogo completo se almacena en un único sitio
20. Integración de Datos
-
Aplicaciones necesitan acceder a datos en lugares
- Diferentes sitios físicos
- Diferentes sitios lógicos (formatos)
-
Modelo para interoperabilidad de datos: mapeos de esquema
- Integración de datos
- Intercambio de datos
Integración de Datos (Data Integration - Data Federation)
- Se consultan datos heterogéneos de diferentes fuentes via un esquema virtual global.
∑₁
|DB1| S₁<------
∑₂ \
|DB2| S₂<------ --- |T| <- CONSULTA
∑₃ /
|DB3| S₃<-----
- Sᵢ: fuentes
- T: esquema global
- ∑ᵢ(T->Sᵢ): mapeos
- Los datos nunca están en T.
- T sólamente convierte la consulta para que distintas fuentes la puedan procesar.
Intercambio de Datos (Data Exchange - Data Translation)
Se transforman datos estructurados bajo un esquema origen en datos estructurados bajo un esquema destino.
∑
S ----------> T
|DBₛ| - - - > |DBₜ|
Schema Mappings
Son piezas fundamentales para la formalización y el estudio de interoperabilidad de datos
- Aserciones en alto nivel que especifican la relación entre dos esquemas
- Separación del diseño de la relación entre esquemas y su implementación
- Fáciles de generar y manejar (semi)automáticamente
- Compilados en scripts SQL/XSLT
∑
S ----------> T
|DBₛ| - - - > |DBₜ|
Mapeo M = (S, T, ∑)
Lenguaje de mapeo de esquemas
-
Usando lógica de Primer Orden (LPO)
-
Copiado (nicknaming): copiar tabla origen a tabla destino y renombrarla
- (∀X₁,⋯,Xₙ)(P(X₁,⋯,Xₙ) ⟹ R(X₁,⋯,Xₙ))
- Proyección (borrado de columna): borrar columnas de tabla origen para formar una tabla destino
- (∀X,Y,Z)(P(X,Y,Z) ⟹ R(X,Y))
- Incorporación de columna: sumar columnas a tabla origen para formar una tabla destino
- (∀X,Y)(P(X,Y) ⟹ (∃Z)(R(X,Y,Z)))
- Descomposición: descomponer tabla origen en una o más tablas destino
- (∀X,Y,Z)(P(X,Y,Z) ⟹ R(X,Y) ∧ T(X,Z))
- Join: hacer join entre dos o más tablas origen para formar tabla destino
- (∀X,Y,Z)(E(X,Y) ∧ F(X,Z) ⟹ R(X,Y,Z))
- Combinaciones de lo anterior
Tuple-Generating Dependencies (TGD)
Restricciones que se refieren a la necesidad de que existan tuplas cuando se cumple una condición de disparo.
-
Parte de la LPO, clase importante de restricciones.
- Poder expresivo
- Propiedades algorítmicas
-
Forma general
∀X ϕ(X) ⟹ ∃Y ψ(X,Y)- X e Y son vectores de variables
- ϕ y ψ son conjunciones de fórmulas atómicas
-
Subclases conocidas
- Dependencias de inclusión (ej claves foráneas)
- Dependencias multivaluadas
Source-to-Target TGDs
- Forma:
∀X ϕ(X) ⟹ ∃Y ψ(X,Y)- ϕ es una conjunción de átomos sobre esquema origen
- ψ es conjunción de átomos sobre esquema destino
-
Ejemplos:
- ∀E ∀C estudiante(E) ∧ anotado(E,C) ⟹ ∃N nota(E,C,N)
- ∀E ∀C estudiante(E) ∧ anotado(E,C) ⟹ ∃N ∃P profesor(P,C) ∧ nota(E,C,N)
-
Generalizan a dos tipos de restricciones
- Local as view: origen -> ...
- Global as view: ... -> destino
-
Se las conoce también como restricciones GLAV (Global-and-Local-as-View)
Soluciones Universales
Solución J para I es universal si existen homomorfismos de J a todas las posibles soluciones de I.
- Dos instancias son homomórficamente equivalentes si existe un homomorfismo I⟹J y otro J⟹I.
Chase
Procedimiento para reparar una BD en relación a un conjunto de dependencias (TGDs)
- Una TGD σ es aplicable a una BD D si body(σ) mapea a átomos en D
- La aplicación de σ sobre D agrega un átomo con nulos "frescos" correspondientes a cada una de las variables cuantificadas en head(σ).
- El procedimiento de chase produce una solución universal.
Solución universal mínima
Dada una instancia J, la subinstancia J' más pequeña homomórficamente equivalente a J se denomina el core de J.
- Toda estructura relacional finita tiene un core.
-
El core es único, módulo isomorfismo.
-
J' es core de J si:
- J'⊆J
- ∃ homomorfismo h: J⟹J'
- ∄ homomorfismo g: J⟹J'' con J''⊂J
-
Decidir si un conjunto es el core de una instancia es NP-hard.
Consultas en intercambio de datos
- Certains Answers: semántica de la respuesta a consultas sobre el esquema destino.
- Se opera sobre mundo abierto: lo que podemos probar/inferir es verdadero, lo que no podemos no necesariamente es falso
- Mundo cerrado: sólo sabemos qué es verdadero, el resto es falso
Cómputo de certain answers
- Computar solución universal (via chase)
- Evaluar la consulta y descartar toda tupla que contenga nulls (no pueden ser parte del resultado)
- Certain answers coincide con hacer la consulta sobre el core.
- certain(Q,I) = Q(J) donde J es el core de I
21. Ontology-based Data Access
Conocimiento ontológico
- Conceptualización: vista abstracta y simplificada del mundo
-
Ontología: esquema de representación que describe una conceptualización formal de un dominio de interés
- Usualmente una teoría lógica que expresa la conceptualización en un lenguaje declarativo
- Facilita el reúso e intercambio de conocimiento
- Define el vocabulario para intercambiar consultas y aserciones entre agentes
-
Cada base de conocimiento o sistema basado en conocimiento está asociado a una conceptualización
- Lo que existe es lo que se representa (aunque puede representarse la incertidumbre y la incompletitud)
- Cuando se usa un formalismo declarativo, el conjunto de objetos se llama universo de discurso
- Este conjunto se refleja en el vocabulario de representación.
22. Gobierno y Calidad de Datos
Tipos de datos
- Registro
- Matriz de datos: conjunto de registros con cantidad fija de atributos (tabla)
- Documentos: vector de términos (atributos)
- Datos de transacciones: cada registro (transacción) involucra un conjunto de items
- Semi estructurado
- XML: lenguaje de marcado usado por la WWW
- Jerárquico, se utiliza mucho para intercambio de información
- JSON: similar a XML
- XML: lenguaje de marcado usado por la WWW
- Grafos
- Redes sociales: grafos que conectan personas
- Ordenados
- Secuenciales: eventos o items con un orden
- Espacio-temporales: en el tiempo
- Stream Data: datos que fluyen de forma contínua y masiva
- Ej: IoT
Calidad de datos
- Si no se invierte dinero y esfuerzo la calidad de datos es mala
- Necesario monitorearla
- El 70% del trabajo de un proyecto de minería de datos se invierte en "acomodar" y "cruzar" datos.
Análisis de calidad
- Análisis univariado
- Valor mínimo, máximo
- Media, mediana, moda, cuartiles, outliers
- Histograma
- Tablas de frecuencia
- Gráficos
- Análisis bivariado
- Coeficiente de correlación
- Tablas de contingencia
- Diagramas de dispersión
- Etc.
- Perfilado de los datos
- Verificar si la nueva información es consistente con los datos previamente leídos
Gobierno de datos
- De acuerdo a la DAMA (Data Management Association), la data resource management (administración de datos) es el "desarrollo y ejecución de arquitecturas, prácticas y procedimientos que manejan adecuadamente las necesidades del ciclo de vida de los datos de una empresa".
- Calidad
- Arquitectura
- Seguridad
- Metadata
- Es un tema de mucha relevancia
Madurez del gobierno de datos
∧ | R
V | GOBERNADO | i
a | PROACTIVO | e
l | REACTIVO | s
o | INDISCIPLINADO | g
r | ∨ o
----------------------------------------------->
Persona, procesos y tecnología
- Indisciplinado
- Decisiones de negocio dependientes de la tecnología
- Datos duplicados e inconsistentes
- Poca flexibilidad para sostener cambios del negocio
- Reactivo
- Negocio influye sobre decisiones
- Información redundante
- Alto costo para mantener múltiples aplicaciones
- Proactivo
- Equipos de negocio y tecnología trabajan colaborativamente
- Datos se ven como un activo de la compañía
- Gobernado
- Modelos de negocio definen las decisiones tecnológicas
- Procesos estandarizados para la gestión de datos
- Decisiones corporativas se toman con datos ciertos
- Beneficios directos por la aplicación del gobierno
Roles
-
Chief Data Officer: Máximo responsable del gobierno de datos
- Liderar el equipo
- Definir o colaborar en la definición sobre el alcance, objetivo, recursos, etc de las iniciativas del programa
- Promover, negociar y justificar cambios en la estrategia de datos
-
Arquitecto de datos
- Desarrollar la arquitectura de datos para atender requerimientos de negocio
- Desarrollar estándares y procedimientos de diseño y modelado de datos
- Supervisar diseño y modelado
- Aprobar características de desarrollo de aplicaciones e interfaces
-
Data owner (de cada dominio): Máxima autoridad de aprobación respecto a los issues de gobierno de datos dentro de su dominio
- Gestiona el ciclo de vida de datos
- Gestiona calidad y riesgo dentro de su dominio
- Colabora en el gobierno de datos corporativo
- Conoce el significado de los datos
-
Data steward: apoyo a los data owners
- Debe comprender los procesos de negocio como los datos
- Escribir e implementar reglas de calidad de datos
- Medir, monitorear, remediar o escalar los problemas
- Forma parte del flujo de gobierno
-
Custodio de datos
- Pertenece a las áreas de IT responsables de las plataformas, sistemas y aplicaciones
- Son soporte a los stewards y owners para facilitar entendimiento a bajo nivel
- Responsabilidad operativa en el flujo de gobierno
- Integridad y seguridad de datos
- Cumplimiento de políticas de gobierno
- Responsabilidad sobre sistemas, aplicaciones, plataformas
Administración de los datos
Datos -------> Información ------> Conocimiento
+ metadata + asunciones
(definición + relaciones
formato + patrones
relevancia)
Administrador de datos
Persona responsable de la administración de datos, perfil funcional.
- Especialista en los "datos" de una organización.
- No es un DBA. El DBA es especialista en un "motor" de base de datos.
Tareas del administrador de datos
-
Diseño lógico
- recolectar y analizar requerimientos
- modelar el negocio basado en requerimientos
- definir standards, asegurar cumplimiento
- conducir sesiones de definición de datos
- manejar y administrar repositorios de metadata y modelado
- colaborar con el DBA en la creación de modelos físicos a partir de los modelos lógicos
-
Definición de datos
- Hay dos lugares donde típicamente se encuentran las definiciones de los datos:
- En la cabeza de las personas
- En los modelos de datos
- Deben coincidir lo más posible
- Mientras más difieran uno de otro, más vulnerable a la baja calidad de los datos es la empresa
- Hay dos lugares donde típicamente se encuentran las definiciones de los datos:
Privacidad
Preocupación creciente
- Numerosas regulaciones internacionales
- Las organizaciones deben cumplir con las normas locales
- Unión Europea: nueva ley garantiza la protección de datos para todos los ciudadanos.
- En Argentina existen numerosos "secretos": estadístico, fiscal, educativo.
- Dirección nacional de datos personales
- Agencia de acceso a la información pública
- Ley de Habeas Data: permite el acceso a la información personal
23. Diseño Avanzado
No hay mucho que poner de esta clase.
24. Data Mining
Extracción de patrones o información interesante de grandes bases de datos.
Descubrimiento del conocimiento (KDD Process)
- Data mining es el core del proceso de descubrimiento del conocimiento.
DATABASES
\
---------> data warehouse
data cleaning \
-----> task-relevant data
Selection \
--------> Pattern evaluation
Data mining \
------> Knowledge
Funcionalidades del Data Mining
-
Descripción de conceptos: Generalizar, resumir y contrastar las características de la información
- Caracterización
- Discriminación
-
Asociación: buscar correlación, Causalidad
- Multi-dimensionales
- Uni-dimensionales
-
Clasificación y predicción: encontrar modelos que describan clases para futuras predicciones
- Árboles de decisión
- Reglas de clasificación
- Redes neuronales
-
Cluster análisis: agrupar datos para formar clases
- Maximizar similtud dentro de la clase
- Minimizar similtud entre distintas clases
-
Análisis de outliers: datos que no respetan el comportamiento general
- Ruido
- Excepciones
- Fraude
- Eventos raros
-
Análisis de tendencias y evolución
- Análisis de regresión
- Patrones secuenciales
- Similitudes
-
Otro tipo de análisis estadísticos
Supervisada: Redes Neuronales
Sistemas capaces de enfrentar problemas que sólo podían ser resueltos por el cerebro humano.
-
Capacidades:
- Aprender
- Adaptarse a nuevas condiciones
- Adaptarse al ruido
- Predecir el estado futuro
-
No son algorítmicas
- No se programan mediante una secuencia de instrucciones
- Generan ellas mismas sus propias "reglas" para asociar salida y entrada
- Aprenden mediante ejemplos
- Aprenden mediante sus propios errores
- Utilizan procesamiento paralelo
-
Pueden ser combinadas con otras herramientas para mejorar performance
- Lógica Difusa
- Algoritmos Genéticos
- Sistemas Expertos
- Estadísticas
- Transformadas de Fourier
- Wavelets
-
Aplicaciones: los mismos problemas que puede resolver el ser humano, pero a gran escala
- Asociación
- Evaluación
- Reconocimiento de patrones
- No se requieren respuestas perfectas, sino rápidas y buenas
- Ejemplo:
- Escenario bursátil: inversiones, comprar, vender, mantener
- Reconocimiento: comparar objetos, se parecen, son el mismo, está modificado
-
Fallas: no son buenas para
- Cálculos precisos
- Procesamiento en serie
- Reconocer cosas que no tengan patrones inherentes
-
Tipos de redes más utilizados
- Perceptrón multicapa
- Hopfield (mapas asociativos)
- Kohonen (autoorganizativos)
Supervisada: Árboles de decisión
- Los nodos internos son preguntas sobre los atributos
-
Las hojas representan respuestas (etiquetas o clases)
-
Generación, fundamentalmente dos pasos
- Construcción
- Todos los ejemplos están en la raíz al principio
- Se dividen de forma recursiva basados en atributos
- Prunning
- Remover ramas que representen outliers
- Construcción
-
Uso de árboles de decisión
- Clasificación de ejemplo desconocido
-
Es posible extraer reglas de clasificación (IF-THEN) a partir de árboles
-
Es necesario evitar el overfitting
- Si hay demasiadas ramas se tiene mala performance en nuevos ejemplos
- Preprunning: no partir un nodo si la mejora que esto produce está debajo de cierto umbral
- Difícil encontrar el umbral
- Postprunning: podar el árbol una vez construído
- Usando un conjunto diferente al de entrenamiento
-
En cada paso de la clasificación se usan datos distintos
- Construcción: training data
- Evaluación del modelo: testing data
Supervisada: Regresión lineal
Se genera un modelo de regresión lineal.
- La relación entre variables es lineal
- Erorres son independientes
- Errores tienen varianza constante
- Errores tienen esperanza igual a cero
-
Error total es la suma de los errores
-
Tipos de regresión lineal
- Simple: sólo se maneja una variable independiente
- Múltiple: maneja varias variables independientes
-
Regresión logística: cuando la variable es dicotómica o politómica (no numérica)
- Se asocia la variable dependiente a su probabilidad de ocurrencia
- El resultado es la probabilidad de ocurrencia del suceso
Clasificación bayesiana
- Aprendizaje probabilístico: se calcula explícitamente la probabilidad de la hipótesis
- Incremental: cada ejemplo de entrenamiento aumenta o disminuye la probabilidad de la hipótesis
- Predicción: se pueden efectuar predicciones, ponderadas por su probabilidad
- El problema de clasificación puede generalizarse a usar bayes a posteriori
No supervisada: Clústering
Colección de objetos
-
Función de distancia
- Similares dentro del cluster
- Diferentes con otros clusters
-
No supervisada: no hay clases predefinidas
-
Aplicaciones típicas
- Como herramienta para tener idea de la distribución de datos
- Como proceso previo a usar otros métodos
-
Clustering jerárquico
- Usa matriz de distancia como criterio
- No requiere cantidad de clusters como parámetro de input
- Clustering no jerárquico
- Construir una partición de n objetos en k clusters
- Requiere especificar cantidad de clusters como parámetro de input (arbitrario)
- Requiere establecer una semilla inicial
No supervisada: reglas de asociación
-
Generar reglas del tipo
IF condicion THEN resultado -
Tipos de reglas
- Útiles: contienen buena calidad de información
- Triviales: ya conocidas en el negocio
- Inexplicables: curiosidades arbitrarias sin aplicación práctica
-
Medidas de calidad de una regla
- Soporte: cantidad de transacciones en donde se encuentra
- Condición y resultado
- Confianza: Cantidad de transacciones que contienen la cláusula condicional
- Condición
- Lift (improvement): capacidad predictiva de la regla
- Si es mayor a 1, la regla tiene valor predictivo
- Soporte: cantidad de transacciones en donde se encuentra
-
Tipos de reglas
- Booleanas vs cuantitativas
- Una dimensión vs varias dimensiones
- Con jerarquía de elementos (taxonomías) vs elementos simples